Stärke der Korrelation
Aus dem Bauch heraus können wir uns die Plots ansehen und „sehen“, ob die beiden Variablen scheinbar „gemeinsam variieren“.
- Datensatz A: x und y ändern sich gemeinsam und scheinen stark zusammenzuhängen.
- Datensatz B: grober Aufwärtstrend; x und y scheinen nur locker zusammenzuhängen.
- Datensatz C: sieht nach zufälliger Streuung aus; x und y scheinen sich nicht gemeinsam zu ändern und sind nicht verbunden.
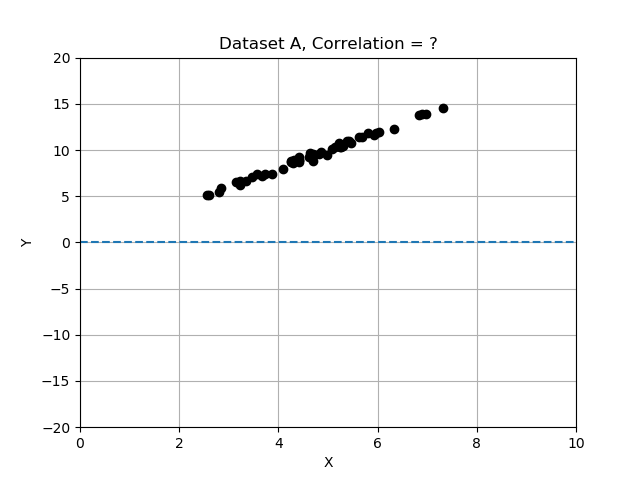
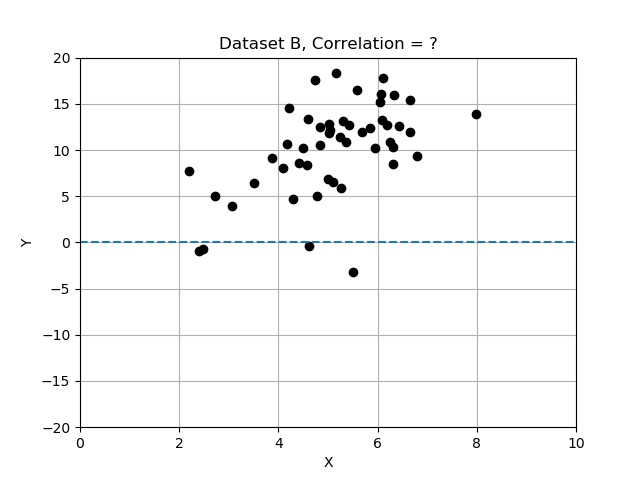
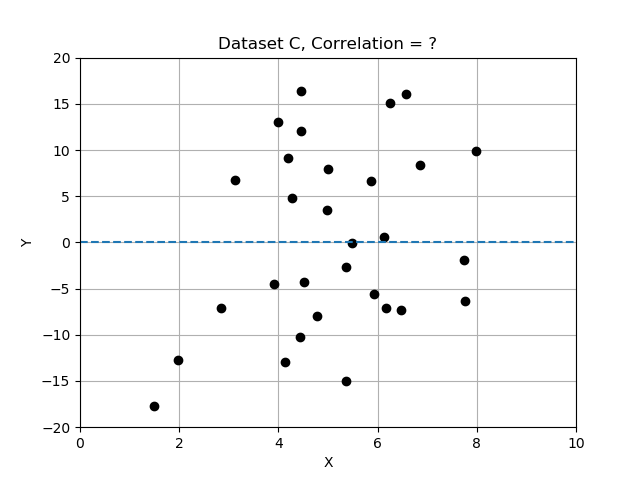
Erinnere dich: Abweichungen sind Differenzen vom Mittelwert, und wir haben normalisiert, indem wir die Abweichungen durch die Standardabweichung geteilt haben. In dieser Übung vergleichst du die 3 Datensätze, indem du die Korrelation berechnest und ermittelst, welcher Datensatz die am stärksten korrelierten Variablen x und y hat. Verwende die bereitgestellte Datentabelle data_sets, ein Dictionary mit Einträgen, die die Schlüssel 'name', 'x', 'y' und 'correlation' enthalten.
Diese Übung ist Teil des Kurses
<Kurs>Einführung in lineares Modellieren mit Python</Kurs>Übungsanweisungen
- Vervollständige die Funktionsdefinition für
correlation()mithilfe des Mittelwerts der Produkte der normalisierten Abweichungen vonxundy. - Iteriere über
data_sets, berechne und speichere jede Korrelation mitcorrelation(record['x'], record['y']). - Führe den Code bis zu diesem Punkt aus (d. h. bis zum Ende der for-Schleife) und inspiziere die Ausgabe. Welcher Datensatz hat die stärkste Korrelation?
- Weise den Namen des Datensatzes (
data_sets['A'],data_sets['B']oderdata_sets['C']) mit der stärksten Korrelation der Variablenbest_datazu.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
# Complete the function that will compute correlation.
def correlation(x,y):
x_dev = x - np.____(x)
y_dev = y - np.____(y)
x_norm = x_dev / np.____(x)
y_norm = y_dev / np.____(y)
return np.____(x_norm * y_norm)
# Compute and store the correlation for each data set in the list.
for name, data in data_sets.items():
data['correlation'] = ____(data['x'], data['y'])
print('data set {} has correlation {:.2f}'.format(name, data['correlation']))
# Assign the data set with the best correlation.
best_data = data_sets['____']