Likelihood maximieren, Teil 1
Zuvor haben wir den Stichproben-mean als Schätzer für den Modellparameter mu der Grundgesamtheit gewählt. Aber woher wissen wir, dass der Stichprobenmittelwert der beste Schätzer ist? Das ist knifflig, daher gehen wir in zwei Schritten vor.
In Teil 1 verwendest du einen rechnerischen Ansatz, um die Log-Likelihood eines gegebenen Schätzwerts zu berechnen. In Teil 2 sehen wir dann, dass bei der Berechnung der Log-Likelihood für viele mögliche Schätzwerte ein Wert die maximale Likelihood liefert.
Diese Übung ist Teil des Kurses
<Kurs>Einführung in lineares Modellieren mit Python</Kurs>Übungsanweisungen
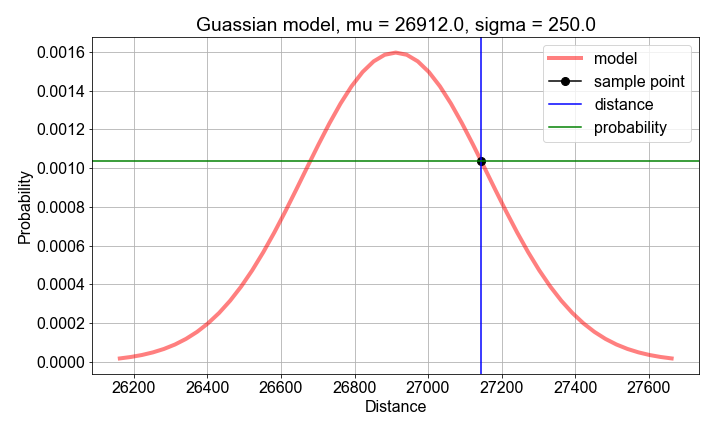
- Berechne
mean()undstd()der vorab geladenensample_distancesals Schätzwerte für die Parameter des Wahrscheinlichkeitsmodells. - Berechne für jede
distancedie Wahrscheinlichkeit mitgaussian_model(), aufgebaut aussample_meanundsample_stdev. - Berechne die
loglikelihoodalssum()deslog()der Wahrscheinlichkeitenprobs.
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
# Compute sample mean and stdev, for use as model parameter value guesses
mu_guess = np.____(sample_distances)
sigma_guess = np.____(sample_distances)
# For each sample distance, compute the probability modeled by the parameter guesses
probs = np.zeros(len(sample_distances))
for n, distance in enumerate(sample_distances):
probs[n] = gaussian_model(____, mu=____, sigma=____)
# Compute and print the log-likelihood as the sum() of the log() of the probabilities
loglikelihood = np.____(np.____(probs))
print('For guesses mu={:0.2f} and sigma={:0.2f}, the loglikelihood={:0.2f}'.format(mu_guess, sigma_guess, ____))