Intensidad de la correlación
De forma intuitiva, podemos mirar los gráficos y "ver" si las dos variables parecen "variar juntas".
- Conjunto de datos A: x e y cambian a la vez y parecen tener una relación fuerte.
- Conjunto de datos B: hay una tendencia ascendente tenue; x e y parecen estar solo débilmente relacionadas.
- Conjunto de datos C: parece una dispersión aleatoria; x e y no parecen cambiar juntas y no están relacionadas.
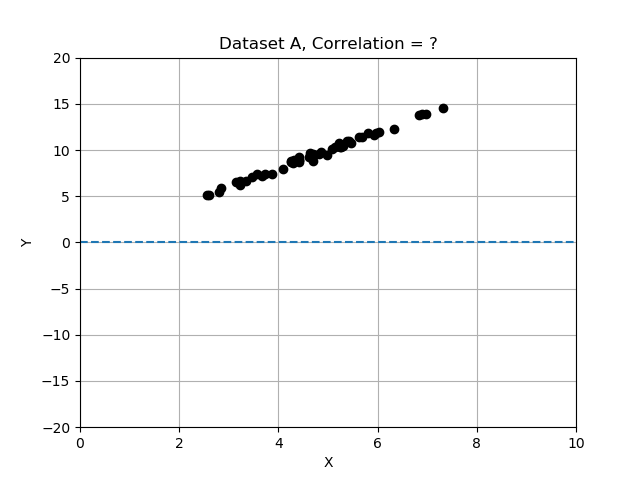
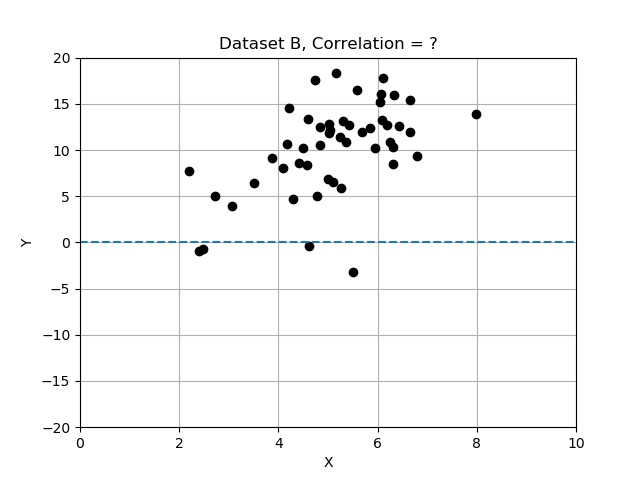
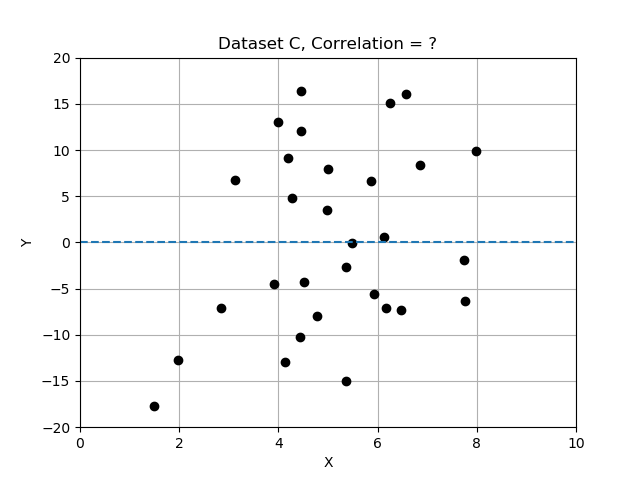
Recuerda que las desviaciones se calculan respecto a la media, y las normalizamos dividiéndolas por la desviación estándar. En este ejercicio compararás los 3 conjuntos de datos calculando la correlación y determinando cuál tiene las variables x e y más fuertemente correlacionadas. Usa la tabla de datos data_sets, un diccionario de registros, cada uno con las claves 'name', 'x', 'y' y 'correlation'.
Este ejercicio forma parte del curso
Introducción al modelado lineal en Python
Instrucciones del ejercicio
- Completa la definición de la función
correlation()usando la media de los productos de las desviaciones normalizadas dexyy. - Itera sobre
data_sets, calculando y almacenando cada correlación concorrelation(record['x'], record['y']). - Ejecuta el código hasta este punto (es decir, hasta el final del bucle for) y revisa lo que se imprime. ¿Qué conjunto de datos tiene la correlación más fuerte?
- Asigna el nombre del conjunto de datos (
data_sets['A'],data_sets['B']odata_sets['C']) con la correlación más fuerte a la variablebest_data.
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
# Complete the function that will compute correlation.
def correlation(x,y):
x_dev = x - np.____(x)
y_dev = y - np.____(y)
x_norm = x_dev / np.____(x)
y_norm = y_dev / np.____(y)
return np.____(x_norm * y_norm)
# Compute and store the correlation for each data set in the list.
for name, data in data_sets.items():
data['correlation'] = ____(data['x'], data['y'])
print('data set {} has correlation {:.2f}'.format(name, data['correlation']))
# Assign the data set with the best correlation.
best_data = data_sets['____']