Data-encoding
Encodering van categorische data maakt ze bruikbaar voor machine learning-algoritmen. R codeert factoren intern, maar encodering is nodig als je je eigen modellen ontwikkelt.
In deze oefening bouw je eerst een lineair model met lm() en ontwikkel je daarna stap voor stap je eigen model.
Bij one-hot-encoding wordt voor elk niveau een aparte kolom aangemaakt.
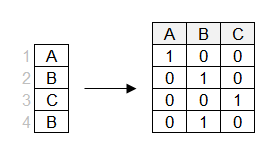
Let op: één van de kolommen is af te leiden uit de andere (bijv. 0'en in de kolommen "B" en "C" betekenen 1 in kolom "A"). Je kunt de eerste kolom dus weglaten voor de lineaire regressie. We behandelen lineaire modellen uitgebreider in het volgende hoofdstuk.
Voor one-hot-encoding kun je dummyVars() uit het caret-pakket gebruiken.
Om het te gebruiken, maak je eerst de encoder aan en transformeer je daarna de gegevensset:
encoder <- dummyVars(~ category, data = df)
predict(encoder, newdata = df)
De complete cases van de enquêtedataset uit het MASS-pakket zijn beschikbaar als survey.
Het caret-pakket is al vooraf geladen.
Deze oefening maakt deel uit van de cursus
Oefenen met statistiek-vragen voor sollicitaties in R
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Fit a linear model
lm(___ ~ Exer, data = ___)