Kódování dat
Kódování kategorických dat je nezbytné pro jejich využití v algoritmech strojového učení. R kóduje faktory interně, ale pro vývoj vlastních modelů je nutné kódování provést ručně.
V tomto cvičení nejprve sestavíš lineární model pomocí lm() a pak si krok za krokem vytvoříš vlastní model.
Při one hot encoding se pro každou úroveň vytvoří samostatný sloupec.
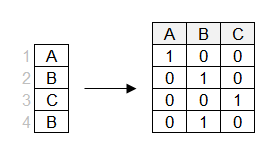
Všimni si, že jeden ze sloupců lze odvodit z ostatních (například samé 0 ve sloupcích „B" a „C" implikují hodnotu 1 ve sloupci „A"). Pro lineární regresi proto můžeš první sloupec vynechat. Lineárním modelům se podrobněji budeme věnovat v další kapitole.
Pro one hot encoding můžeš použít funkci dummyVars() z balíčku caret.
Postup: nejprve vytvoř enkodér a pak transformuj datovou sadu:
encoder <- dummyVars(~ category, data = df)
predict(encoder, newdata = df)
Kompletní záznamy z datové sady průzkumu z balíčku MASS jsou dostupné jako survey.
Balíček caret je předem načten.
Toto cvičení je součástí kurzu
Procvičování statistických otázek k pohovoru v R
Interaktivní cvičení na vyzkoušení si v praxi
Vyzkoušejte si toto cvičení dokončením tohoto ukázkového kódu.
# Fit a linear model
lm(___ ~ Exer, data = ___)