Algoritmus logistické regrese
Pojďme nahlédnout pod pokličku a implementovat algoritmus logistické regrese. Protože funkce glm() v R je velmi komplexní, zaměříš se na implementaci jednoduché logistické regrese pro jeden konkrétní dataset.
Místo součtu čtverců jako metriky chceme použít věrohodnost (likelihood). Logaritmická věrohodnost je ale numericky stabilnější, takže využijeme tu. A ještě jedna změna: protože chceme logaritmickou věrohodnost maximalizovat, ale optim() hledá standardně minimum, je snazší pracovat s negativní logaritmickou věrohodností.
Hodnota logaritmické věrohodnosti pro každé pozorování je:
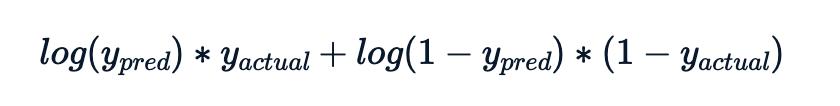
Výsledná metrika je záporný součet těchto příspěvků logaritmické věrohodnosti.
Hodnoty vysvětlující proměnné (sloupec time_since_last_purchase z datasetu churn) jsou dostupné jako x_actual.
Hodnoty závislé proměnné (sloupec has_churned z datasetu churn) jsou dostupné jako y_actual.
Toto cvičení je součástí kurzu
Intermediate Regression in R
Interaktivní cvičení na vyzkoušení si v praxi
Vyzkoušejte si toto cvičení dokončením tohoto ukázkového kódu.
# Set the intercept to 1
intercept <- ___
# Set the slope to 0.5
slope <- ___
# Calculate the predicted y values
y_pred <- ___
# Calculate the log-likelihood for each term
log_likelihoods <- ___
# Calculate minus the sum of the log-likelihoods for each term
___