Classificador de Vizinhos Relacionais
Neste exercício, você vai aplicar um classificador simples baseado em rede chamado relational neighbor classifier.
Ele usa os rótulos de classe dos nós vizinhos para calcular a probabilidade de churn de cada nó na rede.
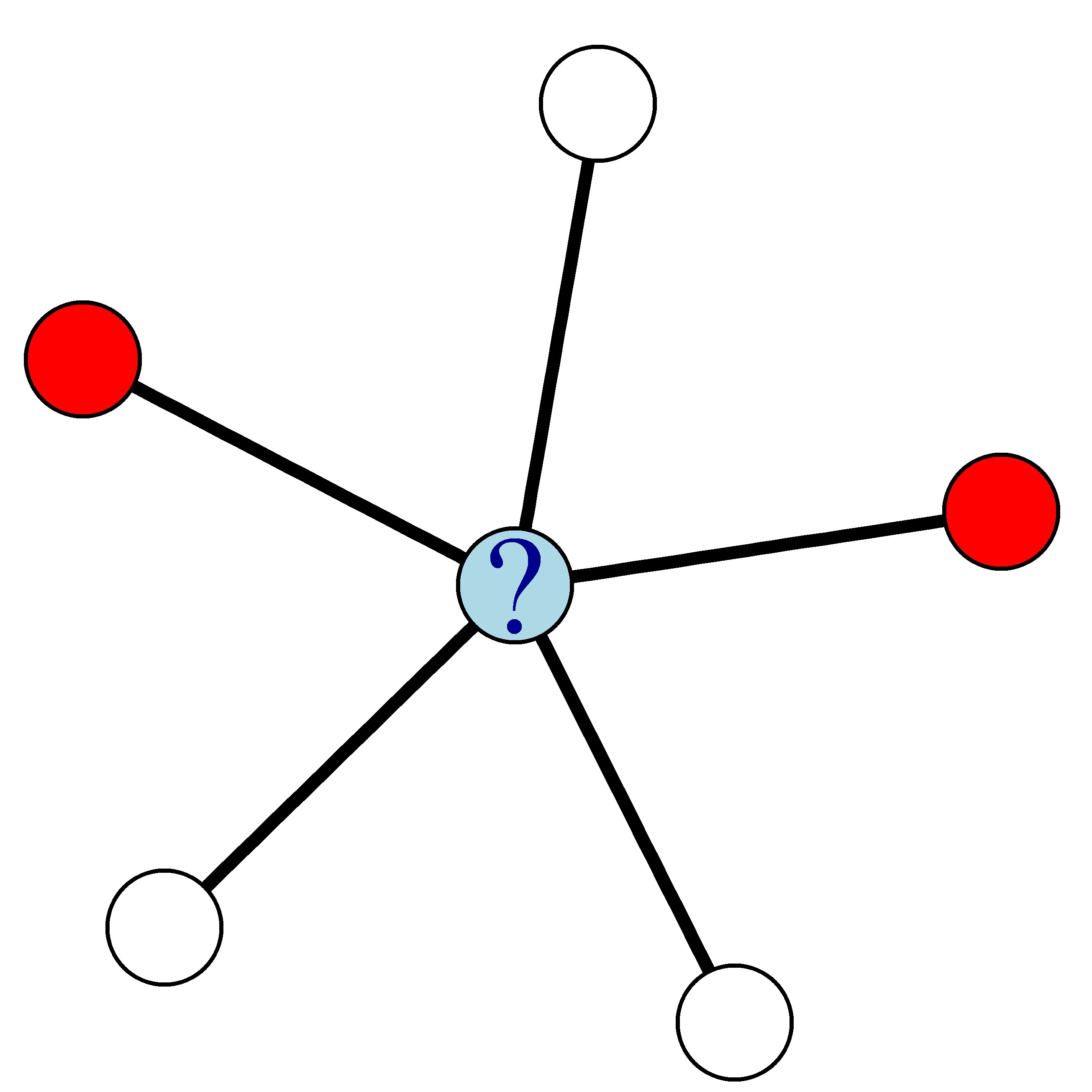
Por exemplo, na rede abaixo, em que os nós vermelhos representam clientes que deram churn e os brancos representam quem não deu churn, a probabilidade de churn do nó azul é 0,4.
Você recebeu dois vetores: ChurnNeighbors e NonChurnNeighbors, com a quantidade de vizinhos de cada cliente que deram churn e que não deram churn, respectivamente.
Este exercicio faz parte do curso
Análise Preditiva com Dados em Rede em R
Instruções do exercicio
- Calcule a probabilidade de churn de cada cliente,
churnProb, usando o classificador de vizinhos relacionais. - Use
which()para encontrar os clientes com a maior probabilidade de churn. Chame esse vetor demostLikelyChurners. - Use
mostLikelyChurnerspara encontrar os IDs dos clientes com a maior probabilidade de churn.
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Compute the churn probabilities
churnProb <- ___ / (ChurnNeighbors + ___)
# Find who is most likely to churn
mostLikelyChurners <- which(churnProb == ___(churnProb))
# Extract the IDs of the most likely churners
customers$id[___]