Extraindo tipos de arestas
Neste exercício, você vai combinar os IDs de cliente no dataframe de clientes com a lista de arestas para descobrir se cada aresta é de churn, não churn ou mista.
Usando a função match(), você vai adicionar duas colunas à lista de arestas.
fromLabelcom o status de churn da colunafromtoLabelcom o status de churn da colunato
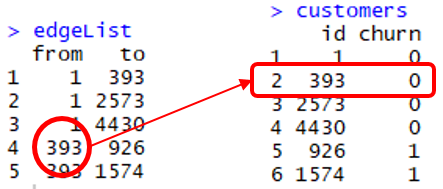
O comando match(x, y) retorna um vetor com a posição de x em y. Na figura acima, match(edgeList$from, customers$id) é 1,1,1,2,2. Por exemplo, a quarta linha em edgeList$from, que é o cliente com id 393, é o segundo elemento em customers$id.
O rótulo de churn desse cliente é, portanto, customers[2,2] ou 0.
Da mesma forma, o rótulo de churn de todos em edgeList$from é customers[match(edgeList$from, customers$id),2].
Este exercicio faz parte do curso
Análise Preditiva com Dados em Rede em R
Instruções do exercicio
- Adicione uma coluna chamada
FromLabelao dataframeedgeListcom o rótulo dos nósfrom, fazendo o match entrecustomers$ideedgeList$frome extraindocustomers$churn. - Faça o mesmo para as arestas
toe chame essa coluna deToLabel. - Adicione uma coluna chamada
edgeTypeao dataframeedgeListque seja a soma das colunasFromLabeleToLabel. - Use a função
table()para ver a quantidade de cada tipo de aresta.
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Add the column edgeList$FromLabel
edgeList$FromLabel <- customers[match(edgeList$___, customers$___), 2]
# Add the column edgeList$ToLabel
edgeList$ToLabel <- customers[___(___, ___), 2]
# Add the column edgeList$edgeType
edgeList$edgeType <- edgeList$___ + edgeList$___
# Count the number of each type of edge
___(edgeList$edgeType)