Classificador Relacional Probabilístico por Vizinhança
Neste exercício, você vai aplicar o classificador relacional probabilístico por vizinhança para inferir probabilidades de churn com base na probabilidade prévia de churn dos outros nós.
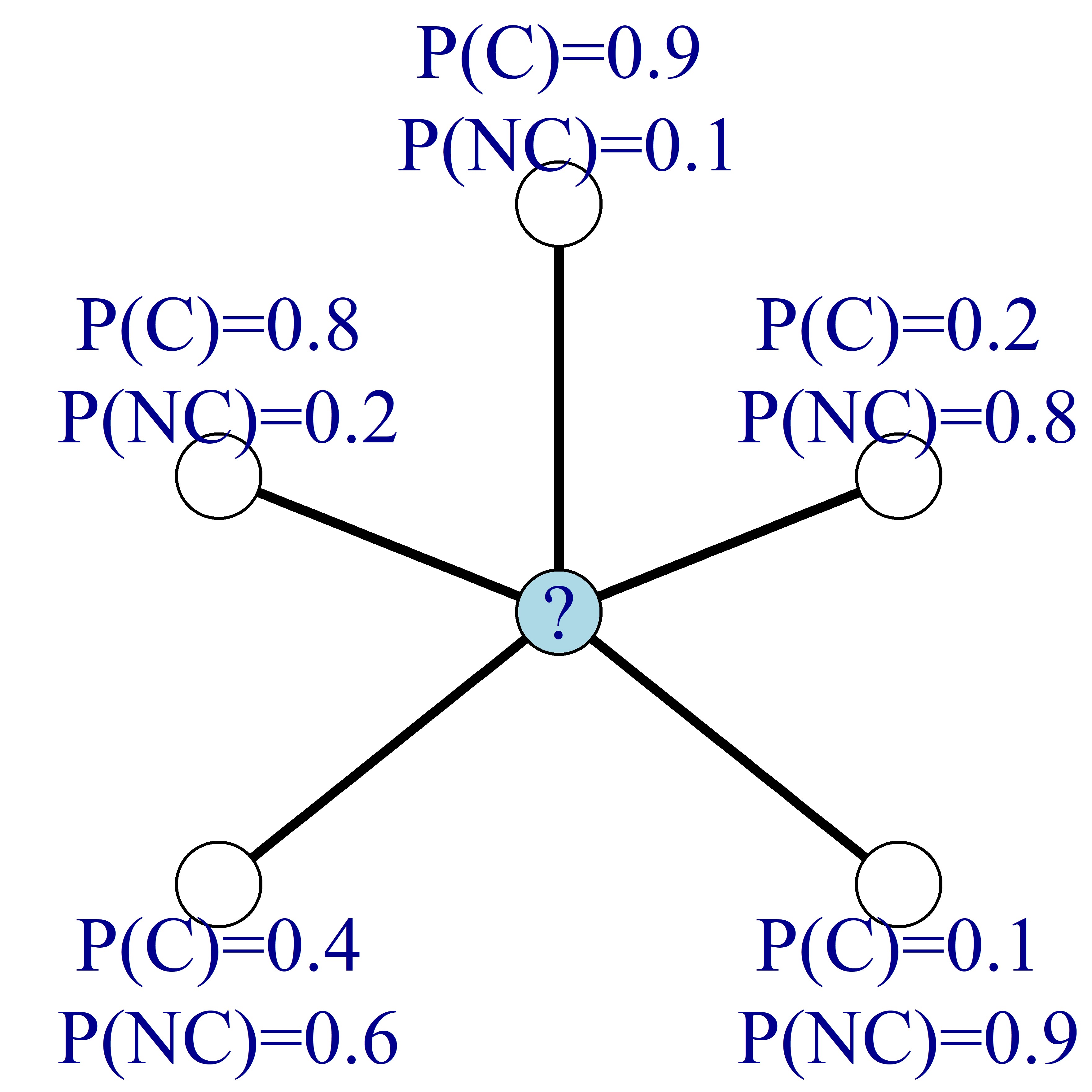
Em vez de conhecer os rótulos dos nós, suponha que você sabe a probabilidade de churn de cada nó, como na imagem abaixo. Na imagem, C significa churn e NC significa não churn.
Então, como antes, você pode atualizar a probabilidade de churn dos nós calculando a média das probabilidades de churn dos nós vizinhos.
Este exercicio faz parte do curso
Análise Preditiva com Dados em Rede em R
Instruções do exercicio
- Encontre a probabilidade de churn do 44º cliente no vetor
churnProb. - Atualize a probabilidade de churn multiplicando
AdjacencyMatrixporchurnProbe dividindo pelo vetorneighbors, que contém os tamanhos das vizinhanças. Adicionamosas.vector()em torno das operações de matriz. Atribua o resultado achurnProb_updated. - Encontre a probabilidade de churn atualizada do 44º cliente no vetor
churnProb_updated. - O que aconteceu com a probabilidade de churn do 44º cliente?.
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Find churn probability of the 44th customer
churnProb[___]
# Update the churn probabilties and the non-churn probabilities
churnProb_updated <- as.vector((AdjacencyMatrix %*% ___) / ___)
# Find updated churn probability of the 44th customer
churnProb_updated[___]