Logistic regression-algoritme
Laten we de interne werking induiken en een logistic regression-algoritme implementeren. Omdat R's glm()-functie erg complex is, blijf je bij het implementeren van simpele logistic regression voor één gegevensset.
In plaats van de som van kwadraten als maatstaf te gebruiken, willen we likelihood gebruiken. Log-likelihood is echter rekenkundig stabieler, dus die gebruiken we. Er is nog één aanpassing: omdat we de log-likelihood willen maximaliseren, maar optim() standaard minima zoekt, is het makkelijker om de negatieve log-likelihood te berekenen.
De log-likelihoodwaarde voor elke observatie is
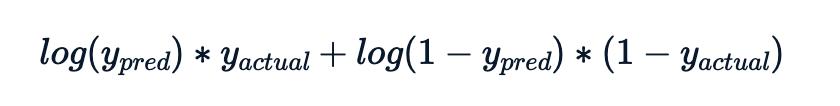
De te berekenen maatstaf is min de som van deze log-likelihood-bijdragen.
De verklarende waarden (de kolom time_since_last_purchase van churn) zijn beschikbaar als x_actual.
De responswaarden (de kolom has_churned van churn) zijn beschikbaar als y_actual.
Deze oefening maakt deel uit van de cursus
Intermediary Regression in R
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Set the intercept to 1
intercept <- ___
# Set the slope to 0.5
slope <- ___
# Calculate the predicted y values
y_pred <- ___
# Calculate the log-likelihood for each term
log_likelihoods <- ___
# Calculate minus the sum of the log-likelihoods for each term
___