Algoritmo di regressione logistica
Entriamo nel dettaglio e implementiamo un algoritmo di regressione logistica. Dato che la funzione glm() di R è molto complessa, ci limiteremo a implementare una regressione logistica semplice per un singolo insieme di dati.
Invece di usare la somma dei quadrati come metrica, vogliamo usare la verosimiglianza. Tuttavia, la log-verosimiglianza è più stabile dal punto di vista computazionale, quindi useremo quella. In realtà, c’è un’ulteriore modifica: dato che vogliamo massimizzare la log-verosimiglianza, ma optim() per impostazione predefinita cerca di minimizzare, è più semplice calcolare la log-verosimiglianza negativa.
Il valore di log-verosimiglianza per ciascuna osservazione è
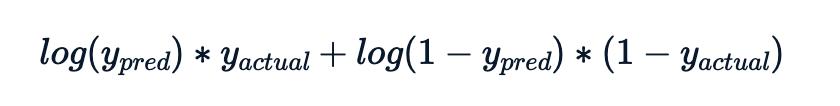
La metrica da calcolare è meno la somma di questi contributi di log-verosimiglianza.
I valori esplicativi (la colonna time_since_last_purchase di churn) sono disponibili come x_actual.
I valori di risposta (la colonna has_churned di churn) sono disponibili come y_actual.
Questo esercizio fa parte del corso
Regressione intermedia in R
esercizio interattivo pratico
Prova questo esercizio completando questo codice di esempio.
# Set the intercept to 1
intercept <- ___
# Set the slope to 0.5
slope <- ___
# Calculate the predicted y values
y_pred <- ___
# Calculate the log-likelihood for each term
log_likelihoods <- ___
# Calculate minus the sum of the log-likelihoods for each term
___