Silhouetmethode
In de vorige les heb je gezien hoe een verschillend aantal clusters de prestaties van je K-Means-algoritme beïnvloedt. Dit is extra belangrijk in een sollicitatiegesprek, omdat het optimale aantal clusters de beste resultaten oplevert.
In deze oefening gebruik je de functie silhouette_score() uit sklearn.metrics op K-Means-algoritmen die zijn gedraaid op de DataFrame diabetes om de Silhouetmethode toe te passen en zo het optimale aantal clusters te vinden. Let op: je gebruikt de euclidische afstand bij het berekenen van de score, zodat deze vergelijkbaar is met de Elbow-methode.
De featurematrix X die je gebruikt om de K-Means-modellen te trainen, is al voor je aangemaakt.
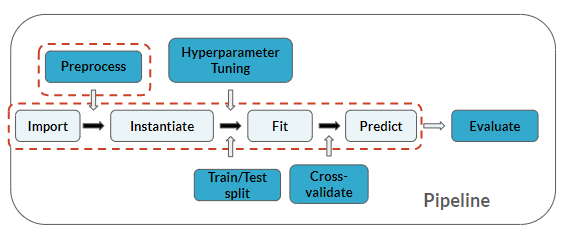
Je staat op hetzelfde punt in de pipeline als in de vorige oefeningen, maar hier voeg je ook voorspellen toe:
Deze oefening maakt deel uit van de cursus
Machine Learning-sollicitatievragen oefenen in Python
Praktische interactieve oefening
Probeer deze oefening eens door deze voorbeeldcode in te vullen.
# Import modules
from sklearn.____ import ____
from sklearn.____ import ____