Metrieken voor onevenwichtige klassen
Klassenonevenwicht kan de prestaties van je model in elke Machine Learning-context belemmeren. Dit is extra relevant in een Machine Learning-sollicitatiegesprek als je wordt gevraagd wat je doet met een gegevensset met een onevenwichtige klasse, omdat sommige data van nature scheef verdeeld zijn, zoals bij verzekeringsfraude.
In deze oefening gebruik je sklearn om een logistisch regressiemodel te maken en print je de confusion matrix samen met meerdere evaluatiemetrieken, zodat je beter leert interpreteren hoe Machine Learning-modellen presteren op gegevenssets met een klassenonevenwicht.
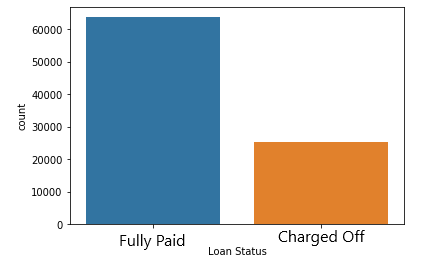
Denk terug aan het klassenonevenwicht dat je eerder in loan_data zag. Het aantal observaties met de leningsstatus Fully Paid is veel groter dan dat van Charged Off:
Deze oefening maakt deel uit van de cursus
Machine Learning-sollicitatievragen oefenen in Python
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Import
from sklearn.____ import ____
from sklearn.____ import ____, ____, ____, ____, _____