Train/test-verdelingen
In een Machine Learning-sollicitatie werk je vrijwel altijd met trainingsdata en testdata. Zoals eerder besproken kan een slecht presterend model het gevolg zijn als de verdelingen van de trainings- en testgegevens verschillen.
In deze oefening gebruik je functies uit sklearn.model_selection en daarnaast seaborn en matplotlib.pyplot om loan_data op te splitsen in een trainingsset en een testset, en om hun verdelingen te visualiseren zodat je eventuele verschillen kunt opsporen.
Let op: seaborn en matplotlib.pyplot zijn al in je werkruimte geïmporteerd en respectievelijk als sns en plt aliased.
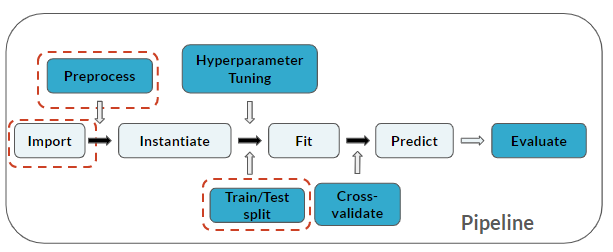
De pijplijn bevat nu Train/Test split:
Deze oefening maakt deel uit van de cursus
Machine Learning-sollicitatievragen oefenen in Python
Oefeninstructies
- Maak een subset van
loan_datamet alleen de featuresCredit ScoreenAnnual Income, en de targetvariabeleLoan Status— in die volgorde. - Maak een 80/20-split van
loan_dataen ken die toe aanloan_data_subset. - Maak pairplots van
trainingSetentestSet(in die volgorde) en zet hethue-argument op de targetvariabeleLoan Status.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Create `loan_data` subset: loan_data_subset
loan_data_subset = ____[['____','____','____']]
# Create train and test sets
trainingSet, testSet = ____(____, ____=___, random_state=123)
# Examine pairplots
plt.figure()
sns.____(____, hue='____', palette='RdBu')
plt.show()
plt.figure()
sns.____(____, hue='____', palette='RdBu')
plt.show()