Log- en machts-transformaties
In de vorige oefening heb je de verdelingen van een trainingsset en testset van loan_data vergeleken. Dit is extra relevant in een Machine Learning-interview, omdat de geobserveerde verdeling bepaalt of je technieken moet gebruiken die je featureverdelingen richting een normale verdeling duwen, zodat aannames over normaliteit niet worden geschonden.
In deze oefening ga je de log- en machts-transformatie uit de module scipy.stats toepassen op de feature Years of Credit History van loan_data, samen met de functie distplot() uit seaborn, die zowel de verdeling als de kernel-dichtheidsschatting (kde) plot.
Alle relevante pakketten zijn al voor je geïmporteerd.
Hier ben je in de pipeline:
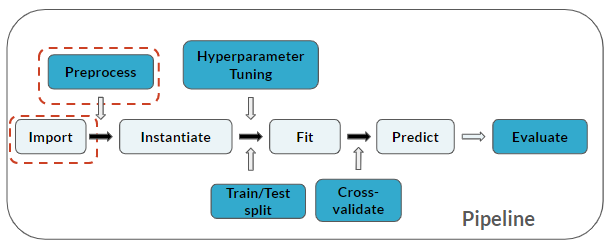
Deze oefening maakt deel uit van de cursus
Machine Learning-sollicitatievragen oefenen in Python
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Subset loan_data
cr_yrs = ____['____']
# Histogram and kernel density estimate
plt.figure()
sns.____(____)
plt.show()