Filter- en wrappermethoden
Vragen over het reduceren van de dimensionaliteit van een gegevensset komen heel vaak voor in Machine Learning-sollicitaties. Eén manier om de dimensionaliteit te verkleinen is door alleen de relevante features in je gegevensset te selecteren.
Hier ga je een filtermethode oefenen op de diabetes DataFrame, gevolgd door 2 verschillende stijlen van wrappermethoden die cross-validatie gebruiken. Je gebruikt pandas, matplotlib.pyplot en seaborn om correlaties te visualiseren, je data te verwerken en featureselectietechnieken op je gegevensset toe te passen.
De featurematrix waarbij de doelfeaturekolom (progression) is verwijderd, is geladen als X, terwijl de doelvariabele is geladen als y.
Let op: pandas, matplotlib.pyplot en seaborn zijn al in je werkruimte geïmporteerd en respectievelijk als pd, plt en sns gealiast.
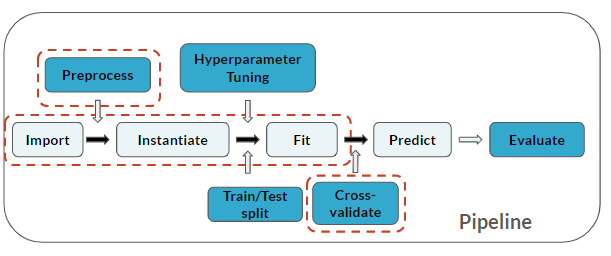
Merk op dat je een Cross-validate-stap aan je pijplijn hebt toegevoegd (die van toepassing is op de laatste 3 stappen):
Deze oefening maakt deel uit van de cursus
Machine Learning-sollicitatievragen oefenen in Python
Praktische interactieve oefening
Probeer deze oefening eens door deze voorbeeldcode in te vullen.
# Create correlation matrix and print it
cor = ____.____()
print(____)
# Correlation matrix heatmap
plt.figure()
sns.____(____, annot=True, cmap=plt.cm.Reds)
plt.show()
# Correlation with output variable
cor_target = abs(cor["progression"])
# Selecting highly correlated features
best_features = ____[____ > ____]
print(____)