Logistic regression-baselineclassificator
In de laatste 2 lessen heb je gezien hoe waardevol featureselectie is in het kader van Machine Learning-interviews. Een andere veelvoorkomende categorie vragen gaat over feature engineering en hoe dit de modelprestaties kan verbeteren.
In deze oefening ga je een nieuwe feature maken op de loan_data-gegevensset uit Hoofdstuk 1. Je vergelijkt vervolgens de accuracy-score van Logistic Regression-modellen op de gegevensset vóór en na feature engineering door de testlabels te vergelijken met de voorspelde waarden van de doeltargetvariabele Loan Status.
Alle relevante pakketten zijn al voor je geïmporteerd: matplotlib.pyplot als plt, seaborn als sns, LogisticRegression uit sklearn.linear_model, train_test_split uit sklearn.model_selection en accuracy_score uit sklearn.metrics.
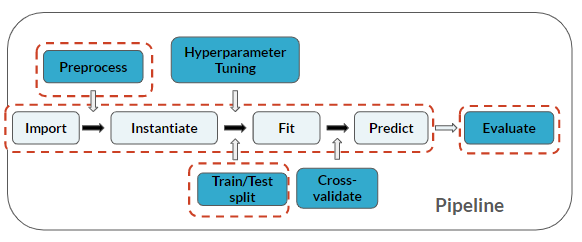
Feature engineering wordt gezien als een stap in de preprocessing vóór het modelleren:
Deze oefening maakt deel uit van de cursus
Machine Learning-sollicitatievragen oefenen in Python
Praktische interactieve oefening
Probeer deze oefening eens door deze voorbeeldcode in te vullen.
# Create X matrix and y array
X = loan_data.____("____", axis=1)
y = loan_data["____"]
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
# Instantiate
logistic = ____()
# Fit
logistic.____(____, ____)
# Predict and print accuracy
print(____(y_true=____, y_pred=logistic.____(____)))