Beslisboom
In de afgelopen drie hoofdstukken heb je verschillende technieken geleerd die je helpen bij veel aspecten van het Machine Learning-interview. In dit hoofdstuk maak je kennis met manieren om ervoor te zorgen dat elk model waar je in een Machine Learning-interview naar wordt gevraagd om te maken of te bespreken, generaliseerbaar is, correct wordt geëvalueerd en goed wordt gekozen uit andere mogelijke modellen.
In deze oefening ga je aan de slag met hyperparametertuning voor een beslisboom op de loan_data-gegevensset.
Hier ga je min_samples_split tunen, het minimumaantal voorbeelden dat nodig is om een extra binaire splitsing te maken, en max_depth, hoe diep je de boom wilt laten groeien. Hoe dieper de boom, hoe meer splitsingen en dus hoe meer informatie over de data wordt vastgelegd.
De feature-matrix X en de doelvariabele y zijn al voor je geïmporteerd.
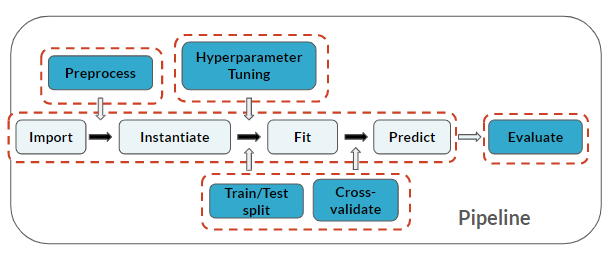
Let op: je doorloopt opnieuw alle stappen van de Machine Learning-pijplijn!
Deze oefening maakt deel uit van de cursus
Machine Learning-sollicitatievragen oefenen in Python
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Import modules
from sklearn.tree import ____
from sklearn.metrics import accuracy_score
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(____, ____, test_size=0.30, random_state=123)
# Instantiate, Fit, Predict
loans_clf = ____()
loans_clf.____(____, ____)
y_pred = loans_clf.____(____)
# Evaluation metric
print("Decision Tree Accuracy: {}".format(____(____,____)))