Clasificador probabilístico de vecinos relacionales
En este ejercicio, vas a aplicar el clasificador probabilístico de vecinos relacionales para inferir probabilidades de churn a partir de la probabilidad previa de churn de los otros nodos.
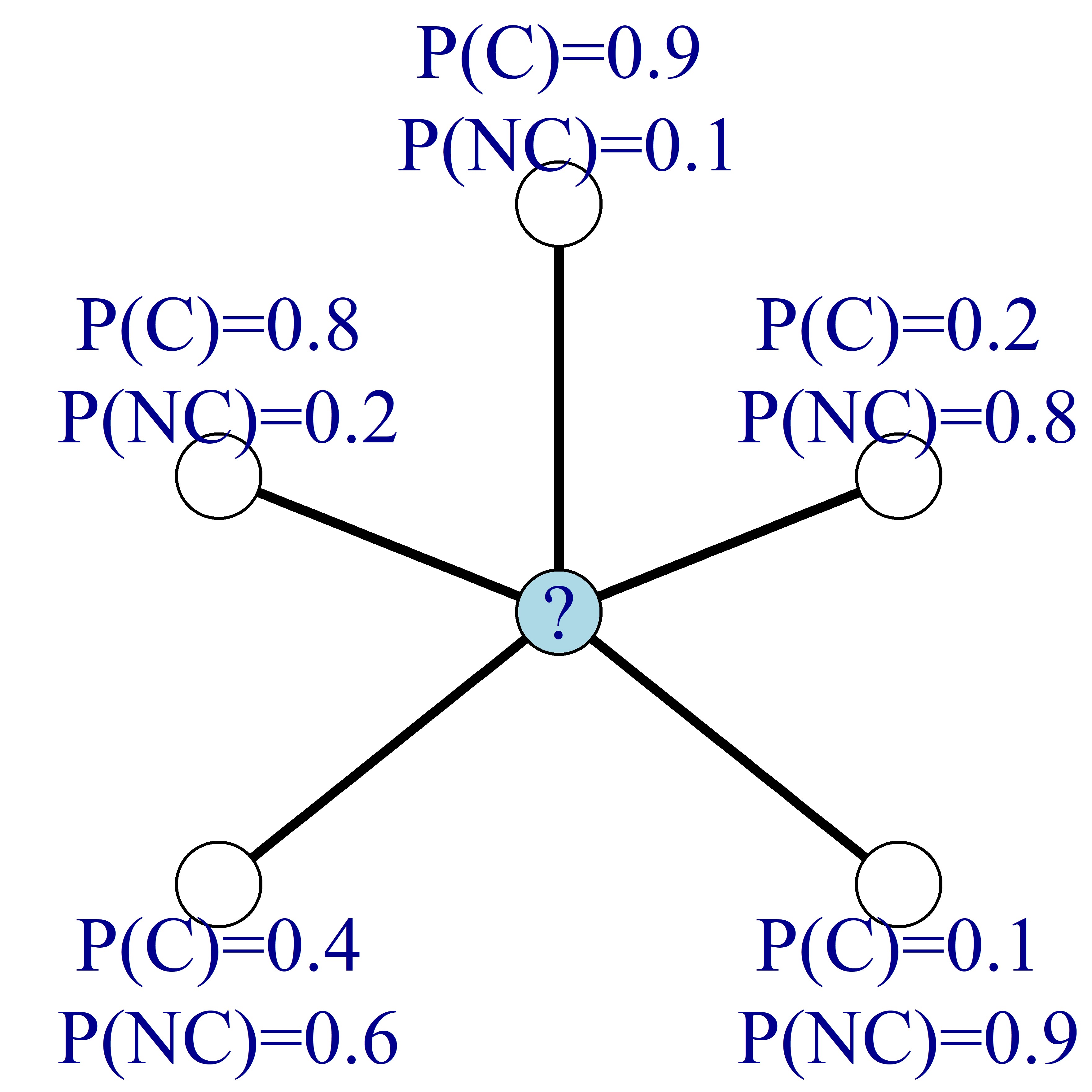
En lugar de conocer las etiquetas de los nodos, supón que conoces la probabilidad de churn de cada nodo, como en la imagen de abajo. En la imagen, C significa churn y NC no churn.
Luego, como antes, puedes actualizar la probabilidad de churn de los nodos calculando la media de las probabilidades de churn de los nodos vecinos.
Este ejercicio forma parte del curso
Analítica predictiva con datos conectados en R
Instrucciones del ejercicio
- Encuentra la probabilidad de churn del cliente 44 en el vector
churnProb. - Actualiza la probabilidad de churn multiplicando
AdjacencyMatrixporchurnProby dividiendo entre el vectorneighbors, que contiene los tamaños de los vecindarios. Hemos añadidoas.vector()alrededor de las operaciones matriciales. Asigna el resultado achurnProb_updated. - Encuentra la probabilidad de churn actualizada del cliente 44 en el vector
churnProb_updated. - ¿Qué le ocurrió a la probabilidad de churn del cliente 44?
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
# Find churn probability of the 44th customer
churnProb[___]
# Update the churn probabilties and the non-churn probabilities
churnProb_updated <- as.vector((AdjacencyMatrix %*% ___) / ___)
# Find updated churn probability of the 44th customer
churnProb_updated[___]