Extraer tipos de aristas
En este ejercicio, vas a hacer coincidir los IDs de cliente del dataframe de clientes con la lista de aristas para determinar si cada arista es de churn, de no churn o mixta.
Usando la función match(), añadirás dos columnas a la lista de aristas.
fromLabelcon el estado de churn de la columnafromtoLabelcon el estado de churn de la columnato
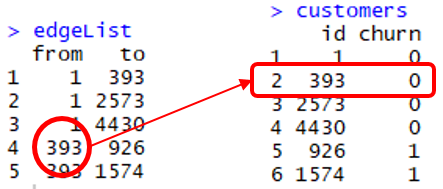
El comando match(x, y) devuelve un vector con la posición de x en y. En la figura anterior, match(edgeList$from, customers$id) es 1,1,1,2,2. Por ejemplo, la cuarta línea de edgeList$from, que es el cliente con id 393, es el segundo elemento en customers$id.
La etiqueta de churn de este cliente es, por tanto, customers[2,2] o 0.
De forma análoga, la etiqueta de churn de todos en edgeList$from es customers[match(edgeList$from, customers$id),2].
Este ejercicio forma parte del curso
Analítica predictiva con datos conectados en R
Instrucciones del ejercicio
- Añade una columna llamada
FromLabelal dataframeedgeListcon la etiqueta de los nodosfromhaciendo coincidircustomers$idconedgeList$fromy extrayendocustomers$churn. - Haz lo mismo para las aristas
to, y llama a esta columnaToLabel. - Añade una columna llamada
edgeTypeal dataframeedgeListque sea la suma de las columnasFromLabelyToLabel. - Usa la función
table()para ver el número de cada tipo de arista.
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
# Add the column edgeList$FromLabel
edgeList$FromLabel <- customers[match(edgeList$___, customers$___), 2]
# Add the column edgeList$ToLabel
edgeList$ToLabel <- customers[___(___, ___), 2]
# Add the column edgeList$edgeType
edgeList$edgeType <- edgeList$___ + edgeList$___
# Count the number of each type of edge
___(edgeList$edgeType)