Datenkodierung
Die Kodierung kategorialer Daten macht sie für Machine-Learning-Algorithmen nutzbar. R kodiert Faktoren zwar intern, aber für die Entwicklung eigener Modelle ist eine explizite Kodierung nötig.
In dieser Übung baust du zuerst ein lineares Modell mit lm() und entwickelst anschließend schrittweise dein eigenes Modell.
Beim One-Hot-Encoding wird für jedes Level eine eigene Spalte erstellt.
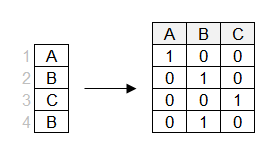
Beachte, dass sich eine der Spalten aus den anderen ableiten lässt (z. B. bedeuten 0 in den Spalten "B" und "C" eine 1 in Spalte "A"). Du kannst also für die lineare Regression die erste Spalte weglassen. Wir schauen uns lineare Modelle im nächsten Kapitel noch genauer an.
Für One-Hot-Encoding kannst du dummyVars() aus dem Paket caret verwenden.
Dazu zuerst den Encoder erstellen und dann den Datensatz transformieren:
encoder <- dummyVars(~ category, data = df)
predict(encoder, newdata = df)
Die vollständigen Fälle des Umfragedatensatzes aus dem MASS-Paket sind als survey verfügbar.
Das Paket caret wurde bereits geladen.
Diese Übung ist Teil des Kurses
<Kurs>Statistik-Interviewfragen in R üben</Kurs>Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
# Fit a linear model
lm(___ ~ Exer, data = ___)