Silhouette method
In the last lesson, you got a taste of how different numbers of clusters affects the performance of your K-Means algorithm. This is especially poignant in the context of an interview, as the optimal number of clusters generates the best results.
In this exercise, you will be using the silhouette_score() function from sklearn.metrics on K-Means algorithms ran on the diabetes DataFrame in order to perform the Silhouette method for finding the optimal number of clusters. Note you will be using euclidian distance when calculating the score as it ensures comparability between it and the Elbow method.
The feature matrix X which you'll use to train the K-Means models has been created for you.
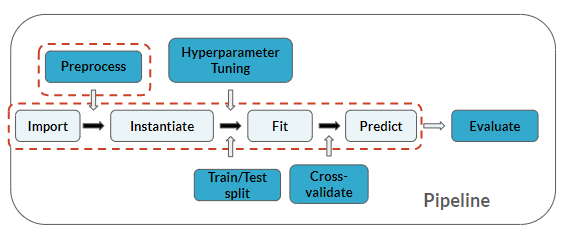
You're at the same place in the pipeline as the last few exercises, but here you'll add predicting as well:
This exercise is part of the course
Practicing Machine Learning Interview Questions in Python
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
# Import modules
from sklearn.____ import ____
from sklearn.____ import ____