Logistic regression baseline classifier
In the last 2 lessons, you learned how valuable feature selection is in the context of machine learning interviews. Another set of common questions you should expect in a machine learning interview pertain to feature engineering, and how they help improve model performance.
In this exercise, you'll engineer a new feature on the loan_data dataset from Chapter 1, compare the accuracy score of Logistic Regression models on the dataset before and after feature engineering by comparing test labels with the predicted values of the target variable Loan Status.
All relevant packages have been imported for you: matplotlib.pyplot as plt, seaborn as sns, LogisticRegression from sklearn.linear_model, train_test_split from sklearn.model_selection, and accuracy_score from sklearn.metrics.
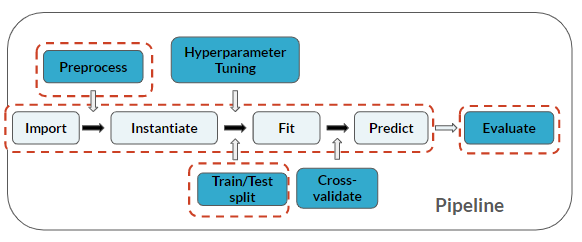
Feature engineering is considered a pre-processing step before modeling:
This exercise is part of the course
Practicing Machine Learning Interview Questions in Python
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
# Create X matrix and y array
X = loan_data.____("____", axis=1)
y = loan_data["____"]
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
# Instantiate
logistic = ____()
# Fit
logistic.____(____, ____)
# Predict and print accuracy
print(____(y_true=____, y_pred=logistic.____(____)))