The hunt for missing values
Questions about processing missing values are integral to any machine learning interview. If you are provided with a dataset with missing values, not addressing them will likely skew your results and lower your model's accuracy.
In this exercise, you'll practice the first pre-processing step by finding and exploring ways to handle missing values using pandas and numpy on a customer loan dataset.
The dataset, which you'll use for many of the exercises in this course, is saved to your workspace as loan_data.
This is where you are in the pipeline:
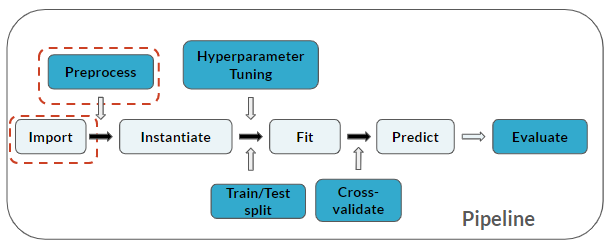
This exercise is part of the course
Practicing Machine Learning Interview Questions in Python
Hands-on interactive exercise
Have a go at this exercise by completing this sample code.
# Import modules
import numpy as np
import pandas as pd
# Print missing values
print(____.____().____())