Relational Neighbor Classifier
In deze oefening pas je een eenvoudige netwerkgebaseerde classifier toe: de relational neighbor classifier. Die gebruikt de klassenlabels van naburige knopen om voor elke knoop in het netwerk een churnkans te berekenen. In het onderstaande netwerk, waar rode knopen churners voorstellen en witte knopen niet-churners, is de churnkans van de blauwe knoop bijvoorbeeld 0,4.
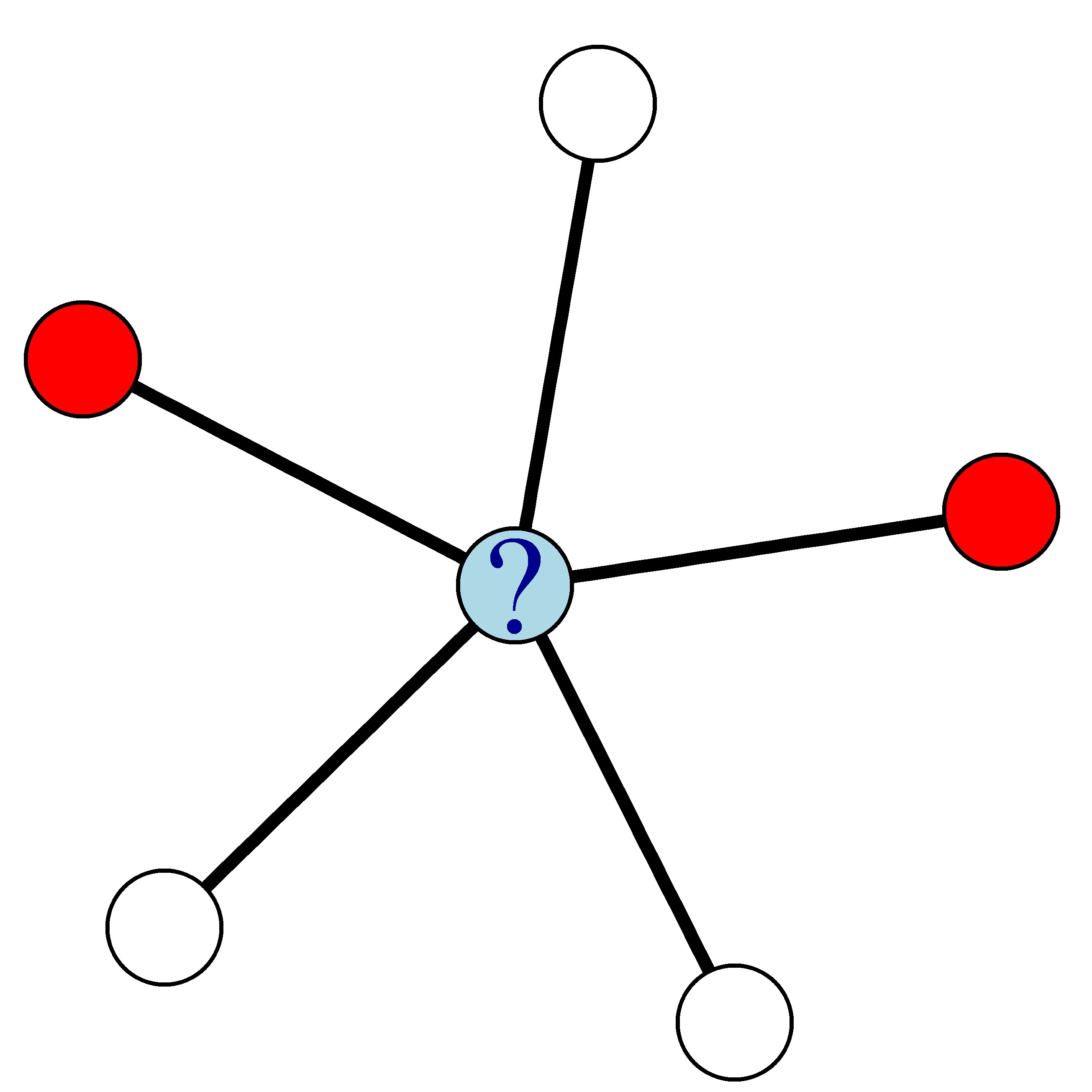
Je krijgt twee vectoren: ChurnNeighbors en NonChurnNeighbors met per klant het aantal buren dat wel en niet gechurned heeft.
Deze oefening maakt deel uit van de cursus
Predictive Analytics met netwerkgdata in R
Oefeninstructies
- Bereken de churnkans van elke klant,
churnProb, met behulp van de relational neighbor classifier. - Gebruik
which()om de klanten met de hoogste churnkans te vinden. Noem deze vectormostLikelyChurners. - Gebruik
mostLikelyChurnersom de ID's te vinden van de klanten met de hoogste churnkans.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Compute the churn probabilities
churnProb <- ___ / (ChurnNeighbors + ___)
# Find who is most likely to churn
mostLikelyChurners <- which(churnProb == ___(churnProb))
# Extract the IDs of the most likely churners
customers$id[___]