Probabilistic Relational Neighbor Classifier
In deze oefening pas je de probabilistic relational neighbor classifier toe om churnkansen af te leiden op basis van de vooraf bekende churnkansen van de andere knopen.
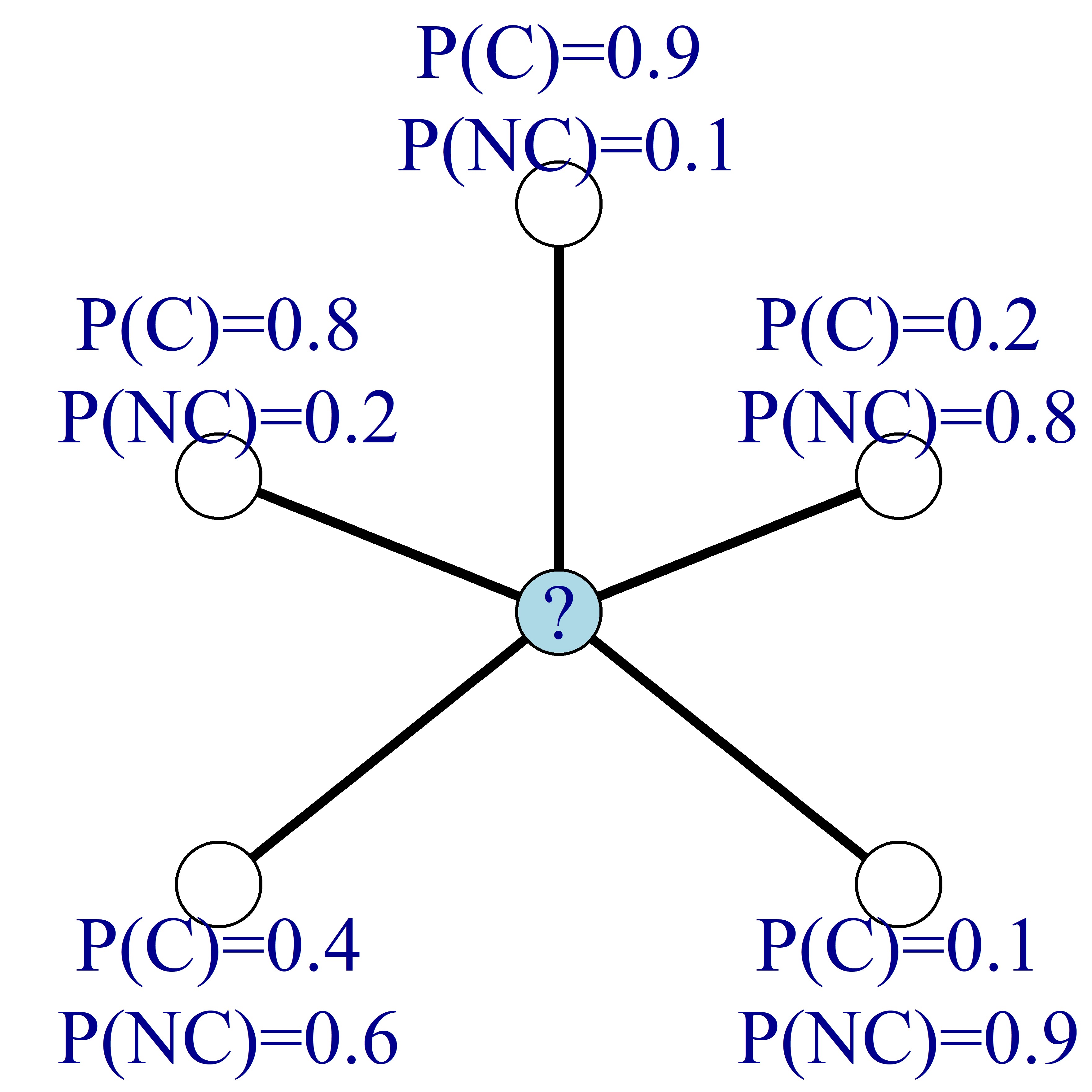
Stel dat je, in plaats van de labels van de knopen te kennen, voor elke knoop de kans op churn kent, zoals in de afbeelding hieronder. In de afbeelding staat C voor churn en NC voor geen churn.
Net als eerder kun je dan de churnkans van de knopen bijwerken door het gemiddelde te nemen van de churnkansen van de aangrenzende knopen.
Deze oefening maakt deel uit van de cursus
Predictive Analytics met netwerkgdata in R
Oefeninstructies
- Zoek de churnkans van de 44e klant in de vector
churnProb. - Werk de churnkans bij door
AdjacencyMatrixte vermenigvuldigen metchurnProben te delen door de vectorneighbors, die de groottes van de buurtschappen bevat. We hebbenas.vector()rond de matrixbewerkingen toegevoegd. Ken het resultaat toe aanchurnProb_updated. - Zoek de bijgewerkte churnkans van de 44e klant in de vector
churnProb_updated. - Wat is er gebeurd met de churnkans van de 44e klant?
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Find churn probability of the 44th customer
churnProb[___]
# Update the churn probabilties and the non-churn probabilities
churnProb_updated <- as.vector((AdjacencyMatrix %*% ___) / ___)
# Find updated churn probability of the 44th customer
churnProb_updated[___]