Método de la silueta
En la última lección viste cómo distintos números de clústeres afectan al rendimiento de tu algoritmo K-Means. Esto cobra especial importancia en una entrevista, ya que el número óptimo de clústeres es el que genera los mejores resultados.
En este ejercicio, utilizarás la función silhouette_score() de sklearn.metrics sobre algoritmos K-Means ejecutados con el DataFrame diabetes para aplicar el método de la silueta y encontrar el número óptimo de clústeres. Ten en cuenta que usarás la distancia euclídea al calcular la puntuación para asegurar la comparabilidad con el método del codo.
La matriz de características X que usarás para entrenar los modelos K-Means ya ha sido creada por ti.
Estás en el mismo punto del pipeline que en los últimos ejercicios, pero aquí además añadirás la predicción:
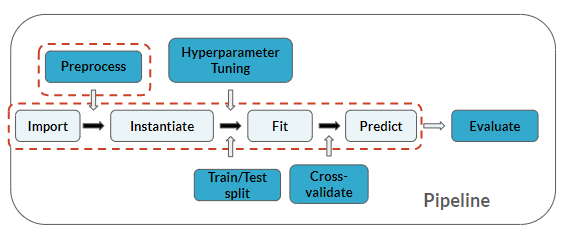
Este ejercicio forma parte del curso
Practicing Machine Learning Interview Questions in Python
Ejercicio interactivo práctico
Prueba este ejercicio y completa el código de muestra.
# Import modules
from sklearn.____ import ____
from sklearn.____ import ____