Clasificador base con regresión logística
En las dos últimas lecciones, aprendiste lo valiosa que es la selección de variables en el contexto de entrevistas de Machine Learning. Otro conjunto de preguntas habituales en estas entrevistas tiene que ver con la ingeniería de características y cómo ayudan a mejorar el rendimiento del modelo.
En este ejercicio, crearás una nueva característica en el conjunto de datos loan_data del Capítulo 1 y compararás la exactitud de modelos de Regresión Logística en el conjunto antes y después de la ingeniería de características, comparando las etiquetas de test con los valores predichos de la variable objetivo Loan Status.
Ya tienes importados todos los paquetes relevantes: matplotlib.pyplot como plt, seaborn como sns, LogisticRegression de sklearn.linear_model, train_test_split de sklearn.model_selection y accuracy_score de sklearn.metrics.
La ingeniería de características se considera un paso de preprocesamiento antes del modelado:
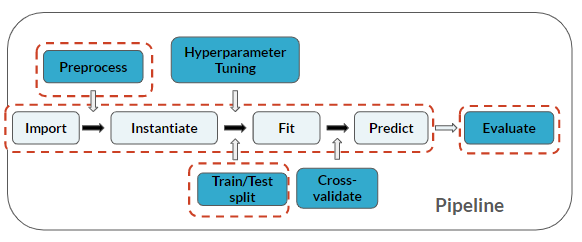
Este ejercicio forma parte del curso
Practicing Machine Learning Interview Questions in Python
Ejercicio interactivo práctico
Prueba este ejercicio y completa el código de muestra.
# Create X matrix and y array
X = loan_data.____("____", axis=1)
y = loan_data["____"]
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
# Instantiate
logistic = ____()
# Fit
logistic.____(____, ____)
# Predict and print accuracy
print(____(y_true=____, y_pred=logistic.____(____)))