Árbol de decisión
En los tres capítulos anteriores has aprendido varias técnicas que te ayudarán a abordar muchos aspectos de una entrevista de Machine Learning. En este capítulo, verás distintas formas de asegurarte de que cualquier modelo que te pidan crear o sobre el que tengas que hablar en una entrevista de Machine Learning sea generalizable, esté bien evaluado y se seleccione correctamente entre otras alternativas.
En este ejercicio, profundizarás en el ajuste de hiperparámetros para un árbol de decisión con el conjunto de datos loan_data.
Aquí ajustarás min_samples_split, que es el número mínimo de muestras necesarias para crear una división binaria adicional, y max_depth, que es la profundidad a la que quieres hacer crecer el árbol. Cuanto más profundo es un árbol, más divisiones tiene y, por tanto, capta más información de los datos.
La matriz de características X y la etiqueta objetivo y ya se han importado por ti.
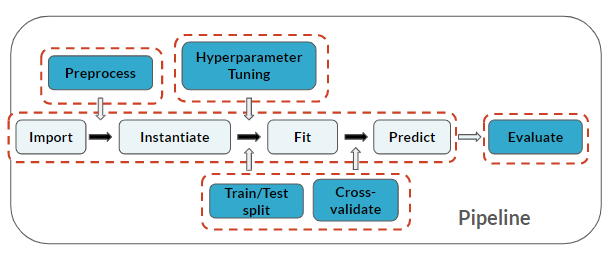
Ten en cuenta que una vez más estás realizando todos los pasos del flujo de trabajo de Machine Learning.
Este ejercicio forma parte del curso
Practicing Machine Learning Interview Questions in Python
ejercicio interactivo práctico
Prueba este ejercicio completando este código de ejemplo.
# Import modules
from sklearn.tree import ____
from sklearn.metrics import accuracy_score
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(____, ____, test_size=0.30, random_state=123)
# Instantiate, Fit, Predict
loans_clf = ____()
loans_clf.____(____, ____)
y_pred = loans_clf.____(____)
# Evaluation metric
print("Decision Tree Accuracy: {}".format(____(____,____)))