Métodos filtro y envolventes
Las preguntas sobre cómo reducir la dimensionalidad de un conjunto de datos son muy habituales en entrevistas de Machine Learning. Una forma de reducir la dimensionalidad es seleccionar únicamente las características relevantes de tu conjunto de datos.
Aquí practicarás un método filtro sobre el DataFrame diabetes, seguido de 2 estilos distintos de métodos envolventes que incluyen validación cruzada. Utilizarás pandas, matplotlib.pyplot y seaborn para visualizar correlaciones, procesar tus datos y aplicar técnicas de selección de características a tu conjunto de datos.
La matriz de características con la columna de la variable objetivo eliminada (progression) está cargada como X, mientras que la variable objetivo está cargada como y.
Ten en cuenta que pandas, matplotlib.pyplot y seaborn ya se han importado en tu espacio de trabajo y se han asignado los alias pd, plt y sns, respectivamente.
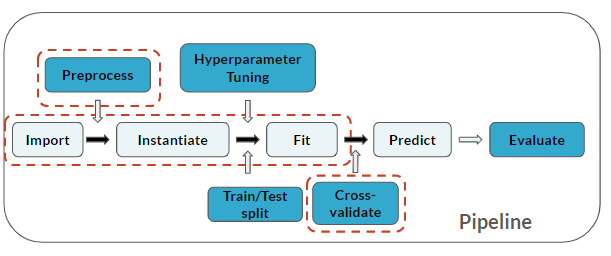
Observa que has añadido un paso de Cross-validate a tu pipeline (que se aplica a los últimos 3 pasos):
Este ejercicio forma parte del curso
Practicing Machine Learning Interview Questions in Python
Ejercicio interactivo práctico
Prueba este ejercicio y completa el código de muestra.
# Create correlation matrix and print it
cor = ____.____()
print(____)
# Correlation matrix heatmap
plt.figure()
sns.____(____, annot=True, cmap=plt.cm.Reds)
plt.show()
# Correlation with output variable
cor_target = abs(cor["progression"])
# Selecting highly correlated features
best_features = ____[____ > ____]
print(____)