Codificação de dados
A codificação de dados categóricos os torna úteis para algoritmos de Machine Learning. O R codifica fatores internamente, mas a codificação é necessária para o desenvolvimento dos seus próprios modelos.
Neste exercício, você vai primeiro ajustar um modelo linear usando lm() e depois desenvolver seu próprio modelo passo a passo.
Na one hot encoding, é criada uma coluna separada para cada um dos níveis.
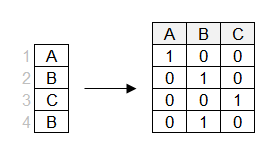
Observe que uma das colunas pode ser derivada com base nas outras (por exemplo, 0 nas colunas "B" e "C" implica 1 na coluna "A"). Então, você pode descartar a primeira coluna para a regressão linear. Vamos revisar modelos lineares com mais detalhes no próximo capítulo.
Para one hot encoding, você pode usar dummyVars() do pacote caret.
Para usá-la, primeiro crie o codificador e depois transforme o conjunto de dados:
encoder <- dummyVars(~ category, data = df)
predict(encoder, newdata = df)
Os casos completos do conjunto de dados da pesquisa do pacote MASS estão disponíveis como survey.
O pacote caret já foi carregado.
Este exercicio faz parte do curso
Praticando perguntas de entrevista de Estatística em R
exercicio interativo prático
Tente este exercicio completando este código de exemplo.
# Fit a linear model
lm(___ ~ Exer, data = ___)