Classifieur probabiliste des voisins relationnels
Dans cet exercice, vous allez appliquer le classifieur probabiliste des voisins relationnels pour déduire des probabilités de churn à partir de la probabilité de churn préalable des autres nœuds.
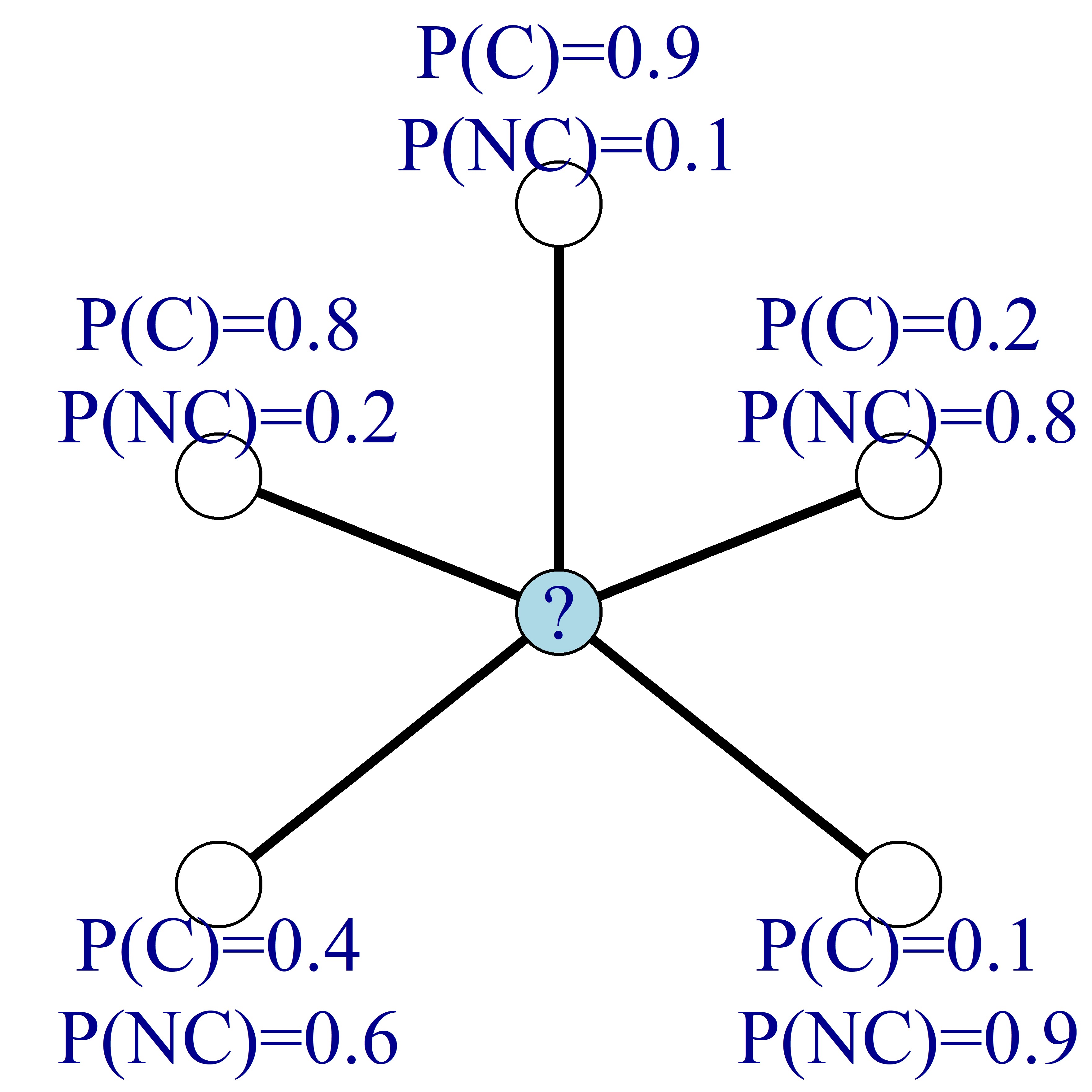
Au lieu de connaître les étiquettes des nœuds, supposez que vous connaissez la probabilité de churn de chaque nœud, comme sur l’image ci-dessous. Sur l’image, C signifie churn et NC non-churn.
Comme précédemment, vous pouvez alors mettre à jour la probabilité de churn des nœuds en calculant la moyenne des probabilités de churn de leurs voisins.
Cet exercice fait partie du cours
<cours>Analytique prédictive avec des données en réseau sous R</cours>Instructions de l’exercice
- Trouvez la probabilité de churn du 44e client dans le vecteur
churnProb. - Mettez à jour la probabilité de churn en multipliant
AdjacencyMatrixparchurnProb, puis en divisant par le vecteurneighborsqui contient les tailles des voisinages. Nous avons ajoutéas.vector()autour des opérations matricielles. Affectez le résultat àchurnProb_updated. - Trouvez la probabilité de churn mise à jour du 44e client dans le vecteur
churnProb_updated. - Qu’est-il arrivé à la probabilité de churn du 44e client ?.
Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
# Find churn probability of the 44th customer
churnProb[___]
# Update the churn probabilties and the non-churn probabilities
churnProb_updated <- as.vector((AdjacencyMatrix %*% ___) / ___)
# Find updated churn probability of the 44th customer
churnProb_updated[___]