Distribution prédictive
Beau travail sur l’analyse des tirages des paramètres ! Passons maintenant aux prédictions avec le modèle de régression linéaire. Combien de clics peut-on espérer si nous décidons d’afficher 10 publicités pour des vêtements et 10 pour des baskets ? Pour le savoir, vous allez échantillonner à partir de la distribution prédictive : une loi normale dont la moyenne est définie par la formule de la régression linéaire et dont l’écart type est estimé par le modèle.
Vous commencerez par résumer l’a posteriori de chaque paramètre par sa moyenne. Ensuite, vous calculerez la moyenne de la distribution prédictive selon l’équation de la régression. Puis, vous tirerez un échantillon de la distribution prédictive et, pour finir, vous en tracerez la densité. Voici la formule de régression pour vous guider :
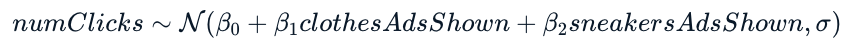
pymc3, numpy et seaborn ont été importés avec leurs alias habituels.
Cet exercice fait partie du cours
<cours>Analyse de données bayésienne en Python</cours>Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
# Aggregate posteriors of the parameters to point estimates
intercept_coef = ____
sneakers_coef = ____
clothes_coef = ____
sd_coef = ____