Probabilistic Relational Neighbor Classifier
In dieser Übung wendest du den probabilistic relational neighbor classifier an, um Kündigungswahrscheinlichkeiten auf Basis der vorherigen Kündigungswahrscheinlichkeit der anderen Knoten zu bestimmen.
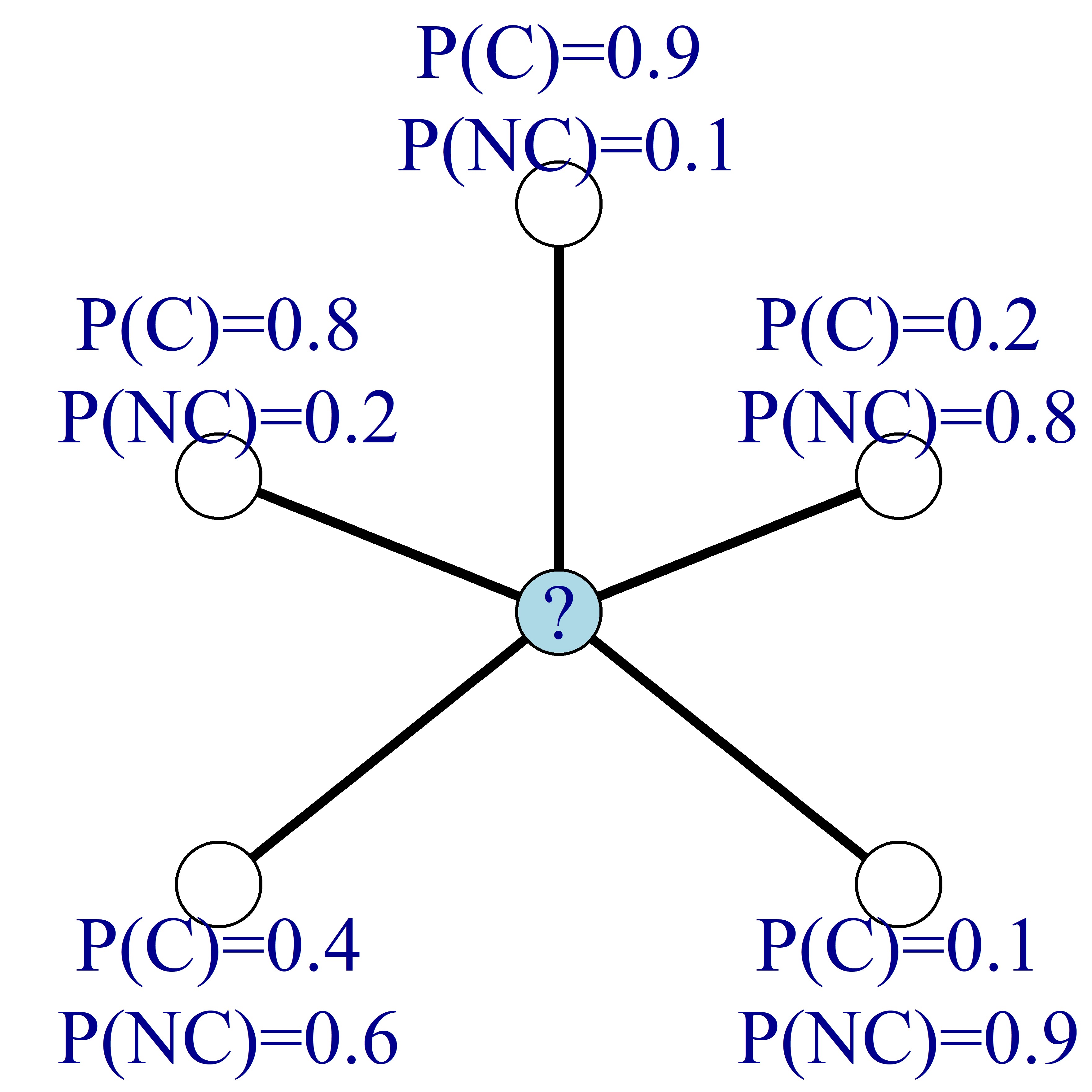
Angenommen, du kennst statt der Labels der Knoten die Kündigungswahrscheinlichkeit jedes Knotens, wie im Bild unten. Im Bild steht C für Kündiger und NC für Nicht-Kündiger.
Dann kannst du – wie zuvor – die Kündigungswahrscheinlichkeit der Knoten aktualisieren, indem du den Durchschnitt der Kündigungswahrscheinlichkeiten der Nachbarknoten bildest.
Diese Übung ist Teil des Kurses
<Kurs>Predictive Analytics mit vernetzten Daten in R</Kurs>Übungsanweisungen
- Ermittle die Kündigungswahrscheinlichkeit des 44. Kunden im Vektor
churnProb. - Aktualisiere die Kündigungswahrscheinlichkeit, indem du
AdjacencyMatrixmitchurnProbmultiplizierst und durch den Vektorneighborsteilst, der die Größen der Nachbarschaften enthält. Wir habenas.vector()um die Matrixoperationen ergänzt. Weise das ErgebnischurnProb_updatedzu. - Ermittle die aktualisierte Kündigungswahrscheinlichkeit des 44. Kunden im Vektor
churnProb_updated. - Was ist mit der Kündigungswahrscheinlichkeit des 44. Kunden passiert?
Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
# Find churn probability of the 44th customer
churnProb[___]
# Update the churn probabilties and the non-churn probabilities
churnProb_updated <- as.vector((AdjacencyMatrix %*% ___) / ___)
# Find updated churn probability of the 44th customer
churnProb_updated[___]