Silhouettenmethode
In der letzten Lektion hast du gesehen, wie sich unterschiedliche Anzahlen von Clustern auf die Leistung deines K-Means-Algorithmus auswirken. Das ist besonders im Interviewkontext wichtig, denn die optimale Clusteranzahl liefert die besten Ergebnisse.
In dieser Übung verwendest du die Funktion silhouette_score() aus sklearn.metrics auf K-Means-Algorithmen, die auf dem DataFrame diabetes ausgeführt werden, um die Silhouettenmethode zur Bestimmung der optimalen Clusteranzahl anzuwenden. Beachte, dass du zur Berechnung des Scores die euklidische Distanz verwendest, um die Vergleichbarkeit mit der Elbow-Methode sicherzustellen.
Die Merkmalsmatrix X, mit der du die K-Means-Modelle trainierst, wurde bereits für dich erstellt.
Du befindest dich an derselben Stelle in der Pipeline wie in den letzten Übungen, ergänzt hier aber zusätzlich das Vorhersagen:
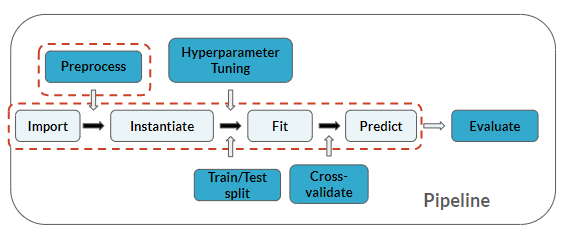
Diese Übung ist Teil des Kurses
ML-Vorstellungsgespräche in Python üben
Interaktive Übung
Vervollständige den Beispielcode, um diese Übung erfolgreich abzuschließen.
# Import modules
from sklearn.____ import ____
from sklearn.____ import ____