Entscheidungsbaum
In den letzten drei Kapiteln hast du eine Reihe von Techniken gelernt, die dir in vielen Bereichen des Machine-Learning-Interviews helfen. In diesem Kapitel lernst du verschiedene Möglichkeiten kennen, um sicherzustellen, dass jedes Modell, das du in einem Interview erstellen oder besprechen sollst, gut generalisiert, korrekt evaluiert und passend aus möglichen Alternativen ausgewählt wird.
In dieser Übung befasst du dich mit dem Tuning von Hyperparametern für einen Entscheidungsbaum auf dem Datensatz loan_data.
Hier wirst du min_samples_split abstimmen, also die minimale Anzahl an Stichproben, die für einen zusätzlichen binären Split erforderlich ist, und max_depth, also wie tief der Baum wachsen soll. Je tiefer ein Baum, desto mehr Splits und desto mehr Informationen über die Daten kann er erfassen.
Die Feature-Matrix X und das Ziel-Label y wurden bereits für dich importiert.
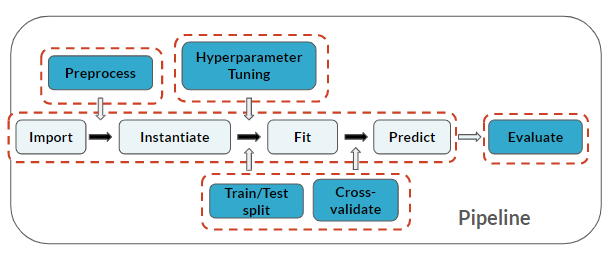
Beachte, dass du hier erneut alle Schritte der Machine-Learning-Pipeline durchläufst!
Diese Übung ist Teil des Kurses
<Kurs>ML-Vorstellungsgespräche in Python üben</Kurs>Interaktive praktische Übung
Versuche dich an dieser Übung, indem du diesen Beispielcode vervollständigst.
# Import modules
from sklearn.tree import ____
from sklearn.metrics import accuracy_score
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(____, ____, test_size=0.30, random_state=123)
# Instantiate, Fit, Predict
loans_clf = ____()
loans_clf.____(____, ____)
y_pred = loans_clf.____(____)
# Evaluation metric
print("Decision Tree Accuracy: {}".format(____(____,____)))