Filter- und Wrapper-Methoden
Fragen zur Reduktion der Dimensionalität eines Datensatzes sind in Machine-Learning-Interviews sehr verbreitet. Eine Möglichkeit, die Dimensionalität zu verringern, ist, nur die relevanten Features deines Datensatzes auszuwählen.
Hier übst du eine Filtermethode am DataFrame diabetes, gefolgt von 2 verschiedenen Varianten von Wrapper-Methoden, die Cross-Validation beinhalten. Du verwendest pandas, matplotlib.pyplot und seaborn, um Korrelationen zu visualisieren, deine Daten zu verarbeiten und Feature-Selection-Techniken auf deinen Datensatz anzuwenden.
Die Feature-Matrix ohne die Zielspalte (progression) ist als X geladen, die Zielvariable als y.
Beachte, dass pandas, matplotlib.pyplot und seaborn bereits importiert und als pd, plt bzw. sns aliasiert wurden.
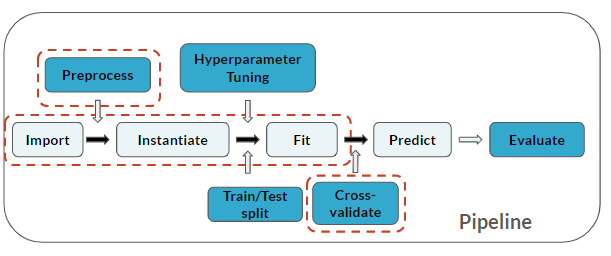
Beachte außerdem, dass du einen Schritt Cross-validate zu deiner Pipeline hinzugefügt hast (der für die letzten 3 Schritte gilt):
Diese Übung ist Teil des Kurses
ML-Vorstellungsgespräche in Python üben
Interaktive Übung
Vervollständige den Beispielcode, um diese Übung erfolgreich abzuschließen.
# Create correlation matrix and print it
cor = ____.____()
print(____)
# Correlation matrix heatmap
plt.figure()
sns.____(____, annot=True, cmap=plt.cm.Reds)
plt.show()
# Correlation with output variable
cor_target = abs(cor["progression"])
# Selecting highly correlated features
best_features = ____[____ > ____]
print(____)