Logistische Regression: Baseline-Klassifikator
In den letzten 2 Lektionen hast du gesehen, wie wertvoll die Merkmalsauswahl in ML-Vorstellungsgesprächen ist. Ein weiterer häufiger Fragenkomplex betrifft das Feature Engineering und wie es die Modellleistung verbessert.
In dieser Übung erstellst du ein neues Merkmal im Datensatz loan_data aus Kapitel 1 und vergleichst die Accuracy von Modellen der logistischen Regression vor und nach dem Feature Engineering, indem du die Test-Labels mit den vorhergesagten Werten der Zielvariable Loan Status vergleichst.
Alle relevanten Pakete sind bereits importiert: matplotlib.pyplot als plt, seaborn als sns, LogisticRegression aus sklearn.linear_model, train_test_split aus sklearn.model_selection und accuracy_score aus sklearn.metrics.
Feature Engineering ist ein Schritt der Vorverarbeitung vor dem Modellieren:
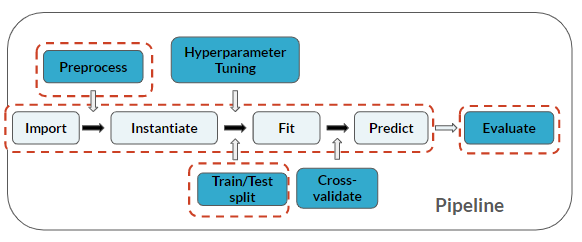
Diese Übung ist Teil des Kurses
ML-Vorstellungsgespräche in Python üben
Interaktive Übung
Vervollständige den Beispielcode, um diese Übung erfolgreich abzuschließen.
# Create X matrix and y array
X = loan_data.____("____", axis=1)
y = loan_data["____"]
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
# Instantiate
logistic = ____()
# Fit
logistic.____(____, ____)
# Predict and print accuracy
print(____(y_true=____, y_pred=logistic.____(____)))