Etiket gürültüsüyle başa çıkma
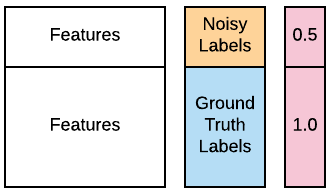
Siber analistlerinden biri, eğitim verilerindeki ilk 100 kaynak bilgisayarın etiketlerinin çoğunun bir veritabanı hatası nedeniyle yanlış olabileceğini söylüyor. Yine de verilerin kullanılabileceğini, çünkü etiketlerin çoğunun doğru kaldığını umuyor; ama bu 100 etiketi “gürültülü” olarak ele almanı istiyor. Neyse ki, ağırlıklı öğrenmeyi kullanarak bunu nasıl yapacağını biliyorsun. Kirlenmiş veri çalışma alanında X_train, X_test, y_train_noisy, y_test olarak mevcut. Ağırlıklı öğrenmeyi kullanarak bir GaussianNB() sınıflandırıcısının performansını iyileştirip iyileştiremeyeceğine bakmak istiyorsun. Çoğu popüler sınıflandırıcının .fit() metodunda desteklenen isteğe bağlı sample_weight parametresini kullanabilirsin. accuracy_score() fonksiyonu önceden yüklendi. Yol göstermek için aşağıdaki görseli inceleyebilirsin.
Bu egzersiz, kursun bir parçasıdır
Python'da Machine Learning İş Akışları Tasarlama
Egzersiz talimatları
- Kirlenmiş etiketlerle eğitim verisine bir
GaussianNB()örneği uydur (fit et). accuracy_score()kullanarak test verisi üzerindeki doğruluğunu raporla.- Gerçek (ground truth) etiketlere, gürültülü etiketlere göre iki kat ağırlık veren ağırlıklar oluştur. Unutma: ağırlıklar eğitim verisi içindir.
- Sınıflandırıcıyı bu ağırlıkları kullanarak yeniden eğit ve doğruluğunu raporla.
Uygulamalı etkileşimli egzersiz
Bu egzersizi bu örnek kodu tamamlayarak deneyin.
# Fit a Gaussian Naive Bayes classifier to the training data
clf = ____.____(____, y_train_noisy)
# Report its accuracy on the test data
print(accuracy_score(y_test, ____.____(X_test)))
# Assign half the weight to the first 100 noisy examples
weights = [____]*100 + [1.0]*(len(____)-100)
# Refit using weights and report accuracy. Has it improved?
clf_weights = GaussianNB().fit(X_train, y_train_noisy, ____=____)
print(accuracy_score(y_test, ____))