Confusion matrix
Met de functie confusion_matrix() van scikit-learn maak je eenvoudig de confusion matrix van je classifier en krijg je een genuanceerder beeld van de prestaties. De functie neemt twee argumenten: de echte labels van je testset - y_test - en je voorspelde labels.
De voorspelde labels van je Random Forest-classifier uit de vorige oefening zijn opgeslagen in y_pred en als volgt berekend:
y_pred = clf.predict(X_test)
Belangrijke opmerking: sklearn berekent standaard de confusion matrix als volgt:
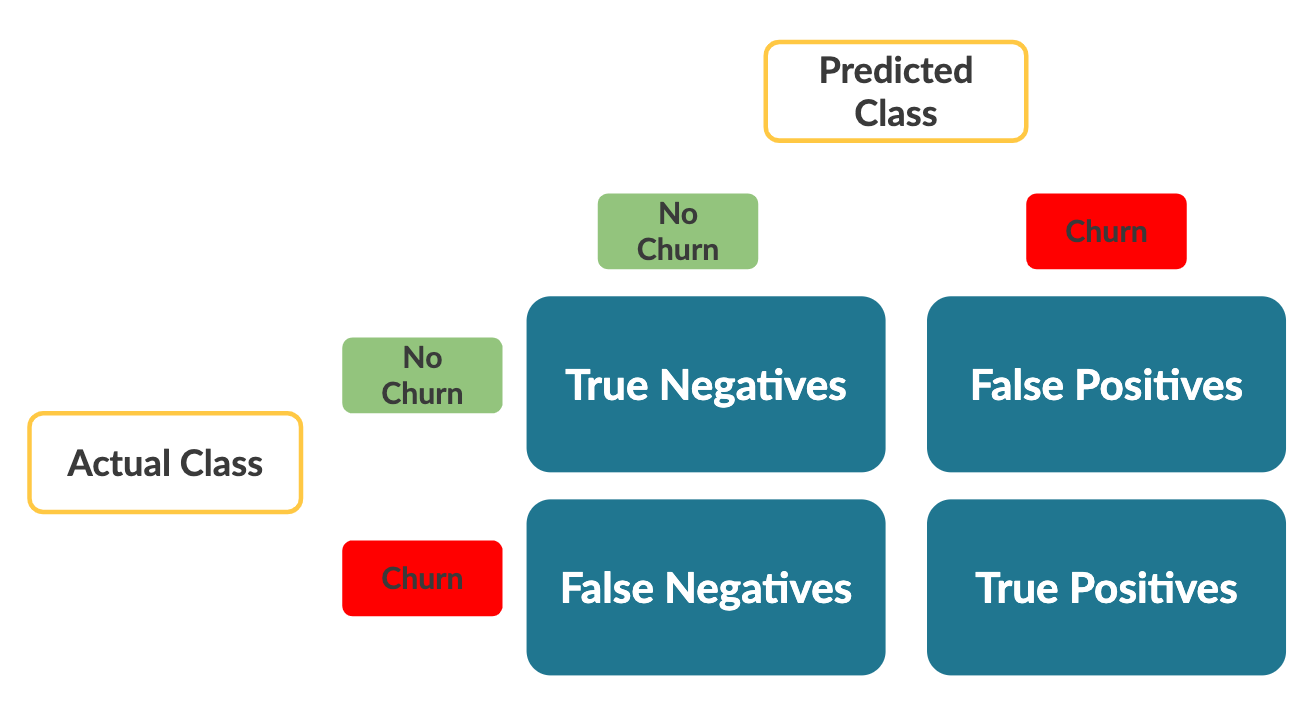
Let op dat de assen het tegenovergestelde zijn van wat je in de video zag. De metrieken zelf blijven hetzelfde, maar houd hier rekening mee bij het interpreteren van de tabel.
Deze oefening maakt deel uit van de cursus
Marketinganalyse: klantverloop voorspellen in Python
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
# Import confusion_matrix