De geclipte surrogaatdoelfunctie
Implementeer de functie calculate_loss() voor PPO. Dit vraagt om het coderen van de kerninnovatie van PPO: de geclipte surrogaat-verliesfunctie. Deze helpt de beleidsupdate te begrenzen, zodat het beleid per stap niet te ver van het vorige beleid afwijkt.
De formule voor de geclipte surrogaatdoelfunctie is
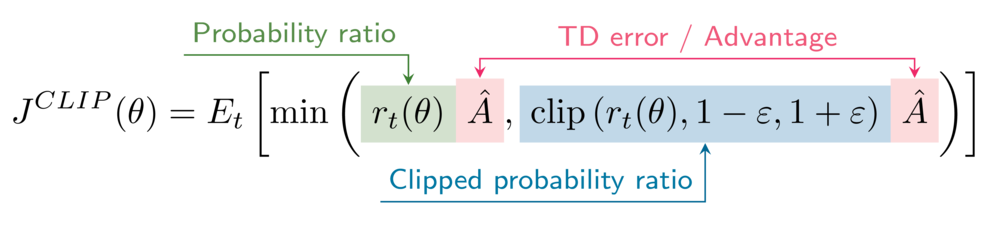
In je omgeving staat de clipping-hyperparameter epsilon op 0,2.
Deze oefening maakt deel uit van de cursus
Deep Reinforcement Learning in Python
Oefeninstructies
- Bepaal de waarschijnlijkheidsratio's tussen
\pi_\thetaen\pi_{\theta_{old}}(ongeclipte en geclipte versies). - Bereken de surrogaatdoelen (ongeclipte en geclipte versies).
- Bereken de geclipte surrogaatdoelfunctie van PPO.
- Bereken het actorverlies.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
def calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done):
value = critic_network(state)
next_value = critic_network(next_state)
td_target = (reward + gamma * next_value * (1-done))
td_error = td_target - value
# Obtain the probability ratios
____, ____ = calculate_ratios(action_log_prob, action_log_prob_old, epsilon=.2)
# Calculate the surrogate objectives
surr1 = ratio * ____.____()
surr2 = clipped_ratio * ____.____()
# Calculate the clipped surrogate objective
objective = torch.min(____, ____)
# Calculate the actor loss
actor_loss = ____
critic_loss = td_error ** 2
return actor_loss, critic_loss
actor_loss, critic_loss = calculate_losses(critic_network, action_log_prob, action_log_prob_old,
reward, state, next_state, done)
print(actor_loss, critic_loss)