De architectuur van het policy-netwerk
Bouw de architectuur voor een Policy Network dat je later kunt gebruiken om je policy gradient-agent te trainen.
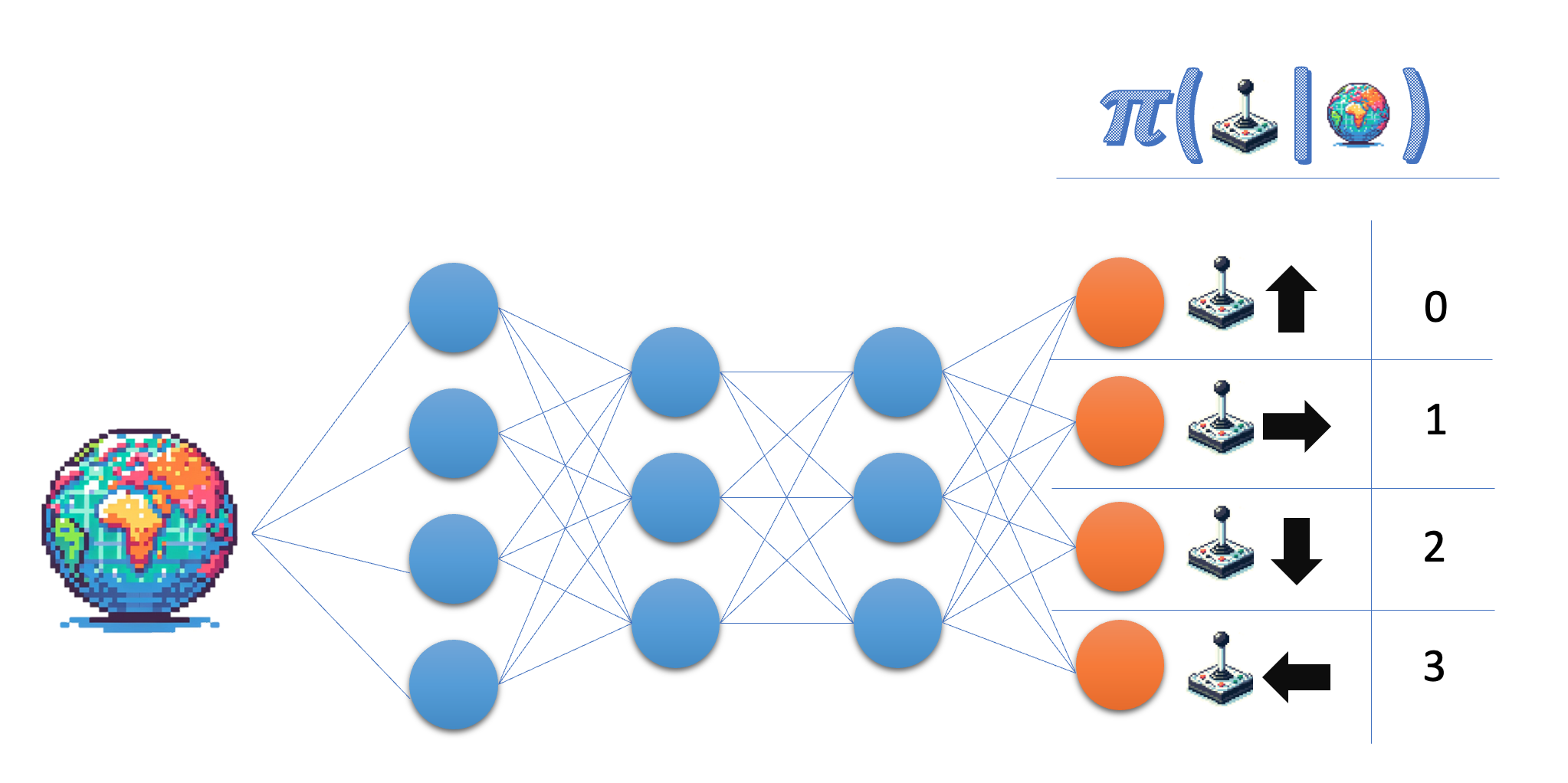
Het policy-netwerk neemt de toestand (state) als input en geeft in de actieruimte een waarschijnlijkheid terug. In de Lunar Lander-omgeving werk je met vier discrete acties, dus je wilt dat je netwerk voor elk van die acties een waarschijnlijkheid uitstuurt.
Deze oefening maakt deel uit van de cursus
Deep Reinforcement Learning in Python
Oefeninstructies
- Geef de grootte op voor de outputlaag van het policy-netwerk; gebruik voor flexibiliteit de variabelenaam in plaats van het daadwerkelijke getal.
- Zorg dat de laatste laag waarschijnlijkheden teruggeeft.
Interactieve oefening met praktijkervaring
Probeer deze oefening door deze voorbeeldcode aan te vullen.
class PolicyNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(PolicyNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
# Give the desired size for the output layer
self.fc3 = nn.Linear(64, ____)
def forward(self, state):
x = torch.relu(self.fc1(torch.tensor(state)))
x = torch.relu(self.fc2(x))
# Obtain the action probabilities
action_probs = ____(self.fc3(x), dim=-1)
return action_probs
policy_network = PolicyNetwork(8, 4)
action_probs = policy_network(state)
print('Action probabilities:', action_probs)