Stappen voor een datapijplijn
Een van je bedrijfskritische datapijplijnen bij Sierra Publishing draait op een datastroom met hoge snelheid, afkomstig van een Kafka-datastream. We moeten de data inlezen en koppelen aan een paar andere gegevenssets.
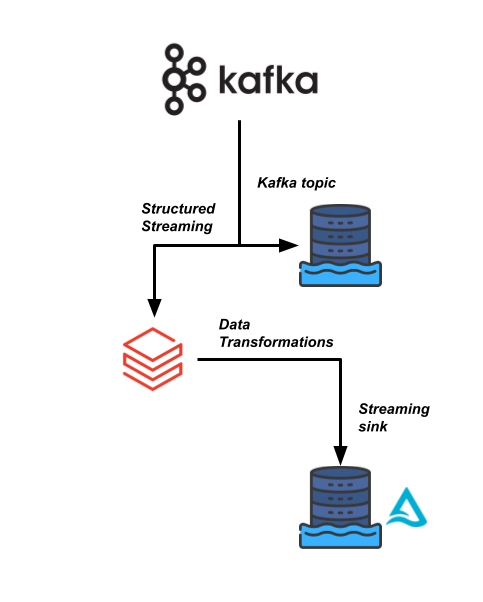
Je data-engineeringteam wil Databricks gebruiken om deze datapijplijn efficiënter te maken en downstream-gebruikers in staat te stellen de data in realtime te lezen voor hun analyses.
Deze oefening maakt deel uit van de cursus
Databricks-concepten
Interactieve oefening met praktijkervaring
Zet theorie om in actie met een van onze interactieve oefeningen
 Begin oefening
Begin oefening