Méthode de la silhouette
Dans la leçon précédente, vous avez vu comment le nombre de clusters influence les performances de votre algorithme K-Means. C’est un point clé en entretien, car le nombre optimal de clusters produit les meilleurs résultats.
Dans cet exercice, vous allez utiliser la fonction silhouette_score() de sklearn.metrics sur des algorithmes K-Means entraînés sur le DataFrame diabetes afin d’appliquer la méthode de la silhouette pour trouver le nombre optimal de clusters. Notez que vous utiliserez la distance euclidienne pour calculer le score afin d’assurer la comparabilité avec la méthode du coude (Elbow method).
La matrice de variables explicatives X que vous utiliserez pour entraîner les modèles K-Means a été créée pour vous.
Vous êtes au même stade du pipeline que lors des derniers exercices, mais ici vous ajoutez également la phase de prédiction :
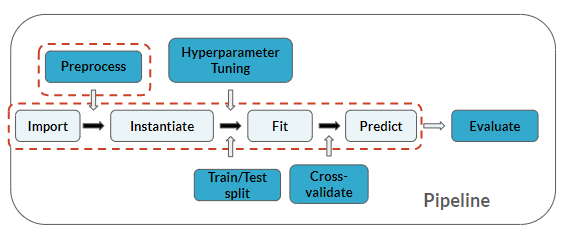
Cet exercice fait partie du cours
S’entraîner aux questions d’entretien en Machine Learning avec Python
Exercice interactif pratique
Essayez cet exercice en complétant cet exemple de code.
# Import modules
from sklearn.____ import ____
from sklearn.____ import ____