Arbre de décision
Au cours des trois chapitres précédents, vous avez découvert toute une série de techniques pour aborder de nombreux aspects d’un entretien en Machine Learning. Dans ce chapitre, vous allez explorer différentes manières de garantir que tout modèle que l’on vous demande de créer ou de commenter lors d’un entretien en Machine Learning soit généralisable, correctement évalué et bien sélectionné parmi d’autres modèles possibles.
Dans cet exercice, vous allez approfondir l’ajustement des hyperparamètres pour un arbre de décision sur le jeu de données loan_data.
Ici, vous allez ajuster min_samples_split, le nombre minimal d’échantillons requis pour créer une division binaire supplémentaire, et max_depth, la profondeur maximale de l’arbre. Plus un arbre est profond, plus il comporte de divisions et plus il capture d’informations sur les données.
La matrice de caractéristiques X et la variable cible y ont été importées pour vous.
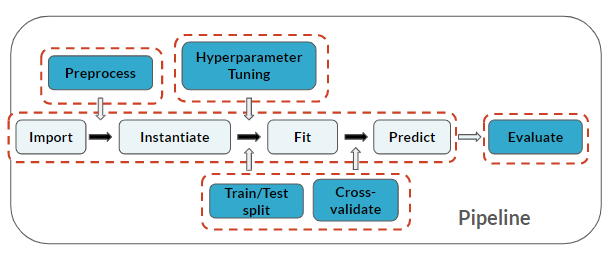
Notez que vous réalisez à nouveau toutes les étapes du pipeline de Machine Learning !
Cet exercice fait partie du cours
<cours>S’entraîner aux questions d’entretien en Machine Learning avec Python</cours>Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
# Import modules
from sklearn.tree import ____
from sklearn.metrics import accuracy_score
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(____, ____, test_size=0.30, random_state=123)
# Instantiate, Fit, Predict
loans_clf = ____()
loans_clf.____(____, ____)
y_pred = loans_clf.____(____)
# Evaluation metric
print("Decision Tree Accuracy: {}".format(____(____,____)))