Classifieur de base en régression logistique
Dans les 2 dernières leçons, vous avez vu à quel point la sélection de variables est précieuse dans le cadre d’entretiens Machine Learning. Un autre type de questions fréquentes concerne le feature engineering, et la manière dont il permet d’améliorer les performances des modèles.
Dans cet exercice, vous allez créer une nouvelle variable sur le jeu de données loan_data du chapitre 1, puis comparer le score de précision de modèles de régression logistique sur le jeu de données avant et après le feature engineering, en comparant les étiquettes de test aux valeurs prédites de la cible Loan Status.
Tous les packages nécessaires ont déjà été importés pour vous : matplotlib.pyplot sous le nom plt, seaborn sous le nom sns, LogisticRegression depuis sklearn.linear_model, train_test_split depuis sklearn.model_selection, et accuracy_score depuis sklearn.metrics.
Le feature engineering est considéré comme une étape de prétraitement avant le modélisation :
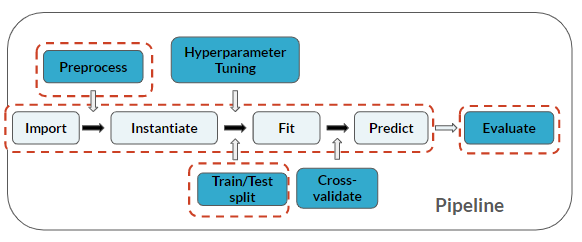
Cet exercice fait partie du cours
S’entraîner aux questions d’entretien en Machine Learning avec Python
Exercice interactif pratique
Essayez cet exercice en complétant cet exemple de code.
# Create X matrix and y array
X = loan_data.____("____", axis=1)
y = loan_data["____"]
# Train/test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=123)
# Instantiate
logistic = ____()
# Fit
logistic.____(____, ____)
# Predict and print accuracy
print(____(y_true=____, y_pred=logistic.____(____)))