Méthodes filtre et « wrapper »
Les questions sur la réduction de la dimension d’un jeu de données sont très fréquentes lors des entretiens en Machine Learning. Une façon de réduire la dimension est de ne sélectionner que les variables pertinentes dans votre jeu de données.
Ici, vous allez pratiquer une méthode filtre sur le DataFrame diabetes, puis 2 variantes de méthodes « wrapper » incluant de la validation croisée. Vous utiliserez pandas, matplotlib.pyplot et seaborn pour visualiser les corrélations, préparer vos données et appliquer des techniques de sélection de variables à votre jeu de données.
La matrice de variables après suppression de la colonne de la variable cible (progression) est chargée sous le nom X, tandis que la variable cible est chargée dans y.
Notez que pandas, matplotlib.pyplot et seaborn ont déjà été importés dans votre espace de travail et abrégés en pd, plt et sns respectivement.
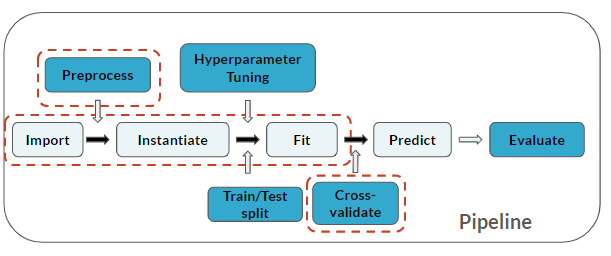
Remarquez que vous avez ajouté une étape de Cross-validate à votre pipeline (qui s’applique aux 3 dernières étapes) :
Cet exercice fait partie du cours
S’entraîner aux questions d’entretien en Machine Learning avec Python
Exercice interactif pratique
Essayez cet exercice en complétant cet exemple de code.
# Create correlation matrix and print it
cor = ____.____()
print(____)
# Correlation matrix heatmap
plt.figure()
sns.____(____, annot=True, cmap=plt.cm.Reds)
plt.show()
# Correlation with output variable
cor_target = abs(cor["progression"])
# Selecting highly correlated features
best_features = ____[____ > ____]
print(____)