Étapes d’un pipeline de données
L’un de vos pipelines de données les plus critiques chez Sierra Publishing repose sur un flux de données à haute vélocité provenant d’un flux Kafka. Nous devons lire ces données et les joindre à quelques autres jeux de données.
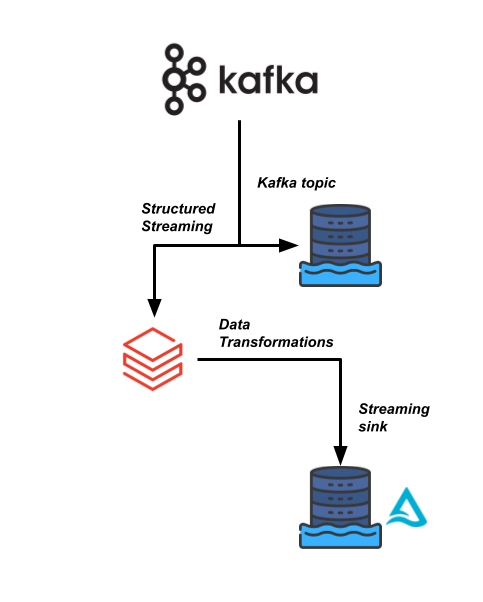
Votre équipe d’ingénierie des données souhaite utiliser Databricks pour rendre ce pipeline plus efficace et permettre aux consommateurs en aval de lire ces données en temps réel pour leurs analyses.
Cet exercice fait partie du cours
<cours>Concepts Databricks</cours>Exercice interactif pratique
Transformez la théorie en action avec l’un de nos exercices interactifs
 Commencer l’exercice
Commencer l’exercice