Performance du portefeuille avec gradient boosting
À ce stade, vous avez étudié la prédiction de la probabilité de défaut à l’aide de LogisticRegression() et de XGBClassifier(). Vous avez examiné certains scores et vu des exemples de prédictions, mais quel est l’impact global sur la performance du portefeuille ? Utilisez la perte attendue pour illustrer l’importance de tester différents modèles.
Un data frame appelé portfolio a été créé pour rassembler les probabilités de défaut des deux modèles, la loss given default (supposée à 20 % pour l’instant), ainsi que loan_amnt, qui sera supposé représenter l’exposition au défaut.
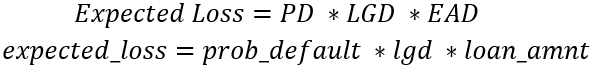
Le data frame cr_loan_prep, ainsi que les ensembles d’entraînement X_train et y_train, ont été chargés dans l’espace de travail.
Cet exercice fait partie du cours
<cours>Modélisation du risque de crédit en Python</cours>Instructions de l’exercice
- Affichez les cinq premières lignes de
portfolio. - Créez la colonne
expected_losspour les modèlesgbtetlr, nomméesgbt_expected_lossetlr_expected_loss. - Affichez la somme de
lr_expected_losspour l’ensemble deportfolio. - Affichez la somme de
gbt_expected_losspour l’ensemble deportfolio.
Exercice interactif pratique
Essayez cet exercice en complétant ce code d’exemple.
# Print the first five rows of the portfolio data frame
print(____.____())
# Create expected loss columns for each model using the formula
portfolio[____] = portfolio[____] * portfolio[____] * portfolio[____]
portfolio[____] = portfolio[____] * portfolio[____] * portfolio[____]
# Print the sum of the expected loss for lr
print('LR expected loss: ', np.____(____[____]))
# Print the sum of the expected loss for gbt
print('GBT expected loss: ', np.____(____[____]))