Métodos filtro e wrapper
Perguntas sobre como reduzir a dimensionalidade de um conjunto de dados são muito comuns em entrevistas de Machine Learning. Uma forma de reduzir a dimensionalidade é selecionando apenas as features relevantes do seu conjunto de dados.
Aqui, você vai praticar um método filtro no DataFrame diabetes, seguido por 2 estilos diferentes de métodos wrapper que incluem validação cruzada. Você usará pandas, matplotlib.pyplot e seaborn para visualizar correlações, processar seus dados e aplicar técnicas de seleção de features ao seu conjunto de dados.
A matriz de features com a coluna da variável-alvo removida (progression) está carregada como X, enquanto a variável-alvo está carregada como y.
Note que pandas, matplotlib.pyplot e seaborn já foram importados no seu ambiente e possuem os aliases pd, plt e sns, respectivamente.
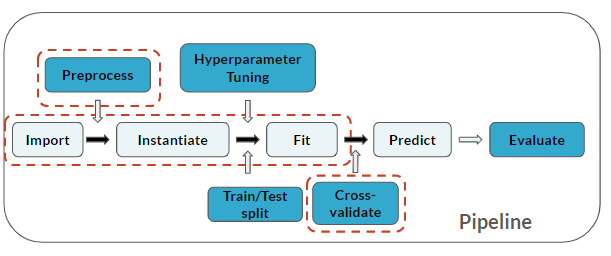
Perceba que você adicionou uma etapa de Cross-validate ao seu pipeline (que se aplica às 3 últimas etapas):
Este exercício faz parte do curso
Praticando perguntas de entrevista de Machine Learning em Python
Exercício interativo prático
Experimente este exercício completando este código de exemplo.
# Create correlation matrix and print it
cor = ____.____()
print(____)
# Correlation matrix heatmap
plt.figure()
sns.____(____, annot=True, cmap=plt.cm.Reds)
plt.show()
# Correlation with output variable
cor_target = abs(cor["progression"])
# Selecting highly correlated features
best_features = ____[____ > ____]
print(____)